YOLOv3是v2的进一步升级,它的论文在此
它的模型借用levio的绘制,如下: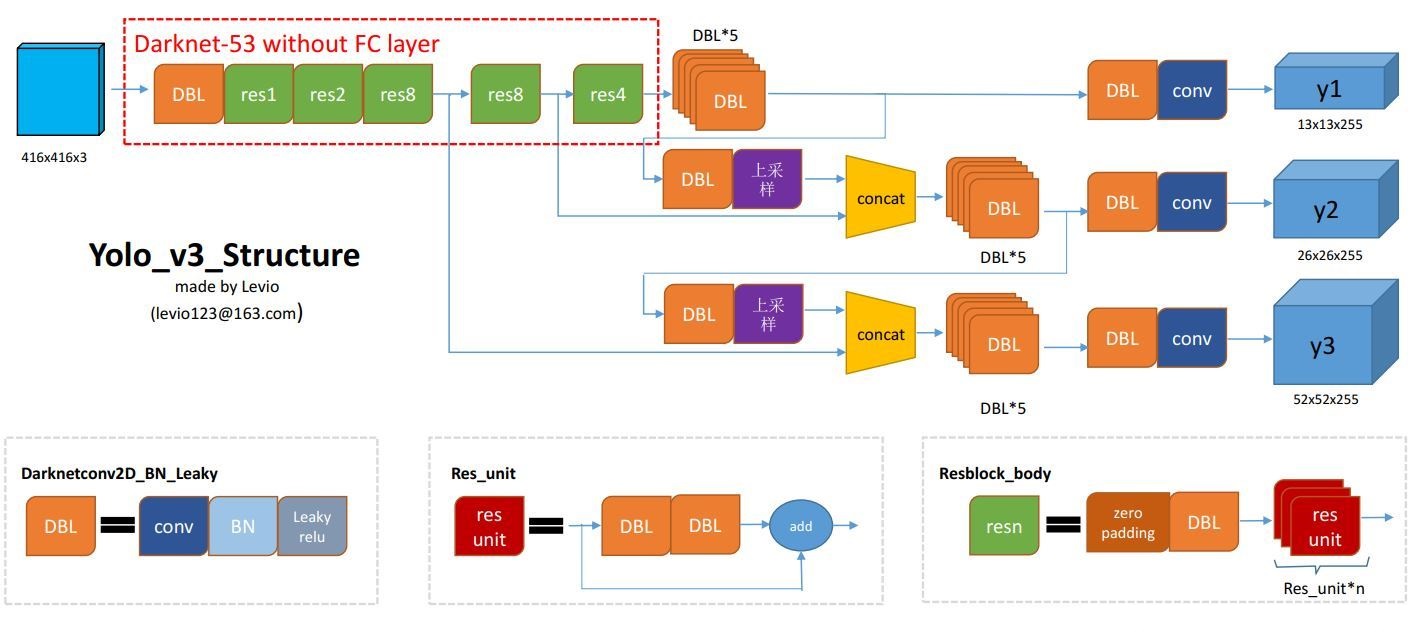
YOLOv3的改进主要在于下面两点:
1)backbone网络从darknet-19变成了darknet-53
2)多尺度预测
1)Backbone: Darknet-53
从YOLOv2到YOLOv3,backbone从darknet-19变成了darknet-53,它们的网络构成的对比如下: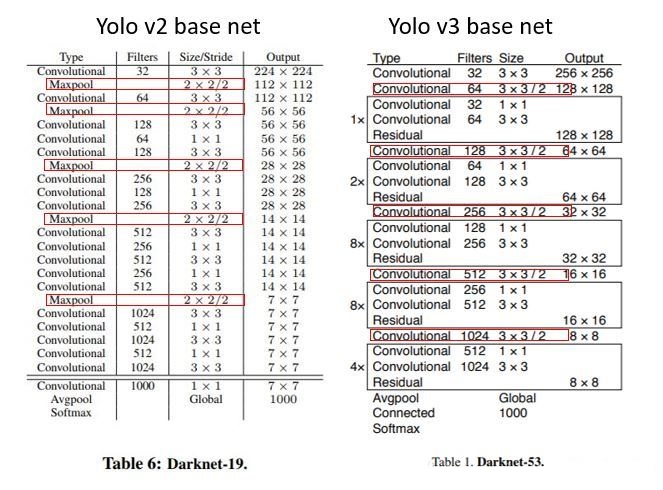
我们看到darknet-53中,是没有池化层和全连接层的。没有池化层,于是图像尺寸的变化就交给了卷积层。
darknet-53的做法是将卷积的步长设置为2,以达到尺寸减半的目的,至于通道数的变化,本就是可以设定的。比如我们看上图:YOLOv2中先经过3x3步长为1的卷积,然后经过2x2步长为2的最大池化,使得图像尺寸减半,接着经过3x3步长为1但通道为64的卷积,使得通道数加倍;对应地YOLOv3中先经过3x3步长为1的卷积,然后再经过3x3步长为2且通道为64的卷积,使得图像尺寸减半但通道数加倍。所以YOLOv3虽然没有池化层但也达到了图像尺寸减半但通道数加倍的效果。
此外可以看到网络中使用的非线性激活函数是LeakyReLU而非传统的ReLU。
来看看LeakyReLU的图像: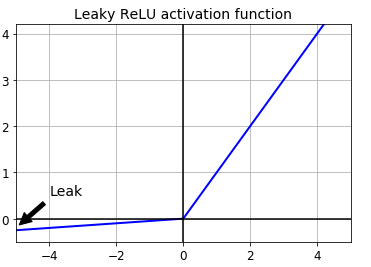
很显然,LeakyReLU给了神经元活着的机会,斜率不大,但足以保证它不会因为输入不大于0而被否定。
使用darknet-53,能达到什么优化呢?这里有一张各个Backbone的精度速度对比图: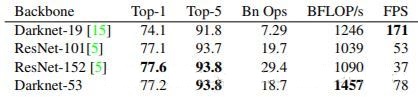
可以看到darknet-53的速度比darknet-19还是要慢很多的,但是它在精度上有了很大提高。说明YOLOv3的初衷并非是追求速度的。
不过,从实践意义上来说,backbone设计并非固定的。在YOLO的官方代码( https://pjreddie.com/darknet )中,只需要改一行,即可切换backbone,这时候你甚至可以选择更轻量级的tiny-darknet以实现极速预测效果,但精度就不可保证了。
2)Predictions across scales
YOLOv3借鉴了FPN里的多尺度预测,这个在SSD里面也使用过
我们看levio绘制的图的输出部分: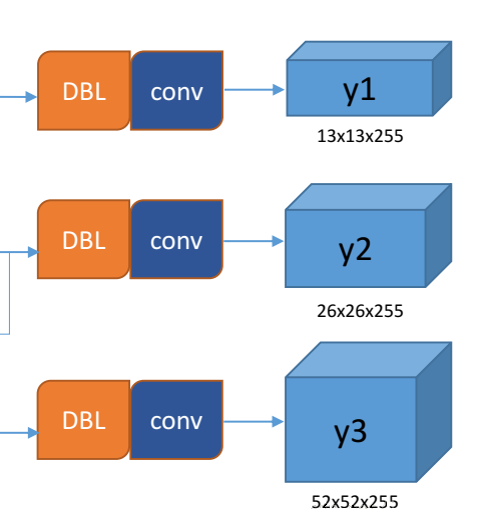
一共输出了三个尺度:13x13,26x26,52x52, 其中主要讲一下两个点:上采样和concat
a)上采样
上采样可以通过和反池化和反卷积比较来理解: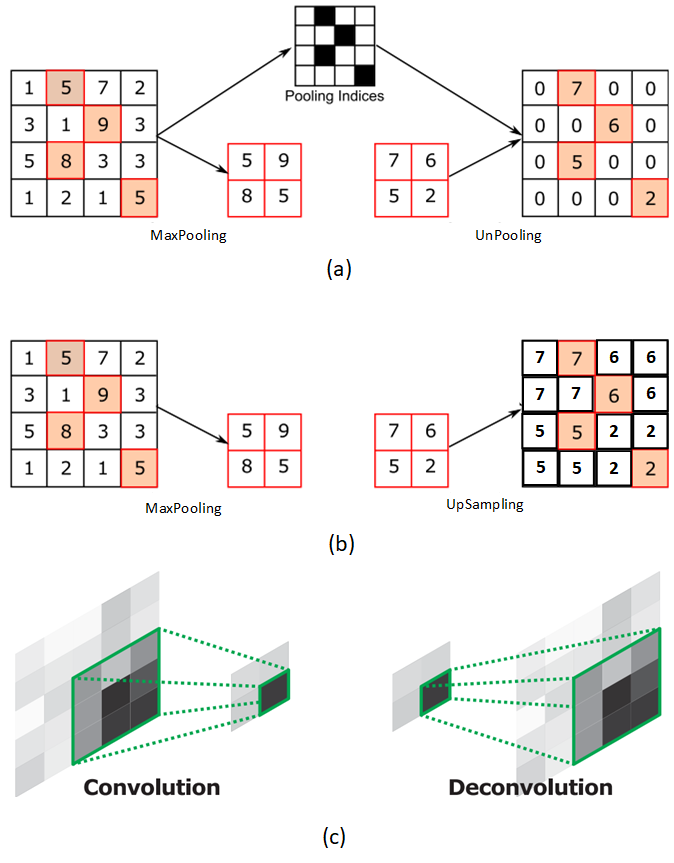
在生成26x26的路径上的上采样就是采用了2倍上采样将13x13转换为26x26,同理52x52路径上的上采样也是26x26使用2倍上采样变为52x52
b)concat
这里拼接的基本要求就是两个数据的shape必须一致,拼接的是通道数方向。
以26x26的路径为例,上采样后的feature map为26x26x256,然后和来自Darknet-53的第152层的输出(26x26x512)进行拼接,得到26x26x768。
拼接的意义是什么呢?我试着去理解:首先,我们可以认为更早期的feature map(比如来自Darknet-53的第152层)还不是那么抽象,所以它会含有更多的全局信息。那么拼接上这些早期map,就能够兼顾全局和局部信息。虽然这有点玄学,但是深度学习的解释性往往如此抽象,幸运的是作者提出的模型在数据上的表现说是work的。
我们再来关注一下输出的通道数。都是255,作为预测数据,每一位必须有它实际的意义。
首先对COCO类别而言,有80个种类,YOLOv3中每个网格单元预测3个box,每个box有5个参数即(x, y, w, h, confidence)
加起来就是3*(5 + 80) = 255
主要的改进就讲到这里。当然YOLOv3相对于v2还有一些别的改进值得一提:
1)聚类方法选定的Anchor Box达到了9个
2)分类输出分类由softmax改成logistic(这样一个对象可以有多标签,比如一个人有Woman 和 Person两个标签)
以上。