论文见此
SSD算法全称为Single Shot MultiBox Detector,它和YOLO一样,是一种one-stage的检测方法,区别于RCNN系列的proposal+predict的two-stage方法。
SSD是基于YOLO进行改进的,它主要改进的地方有三点:
1)多次取各种大小的特征图进行多次目标检测。 大特征图(分辨率更高)检测小目标,小特征图(分辨率低)检测大目标。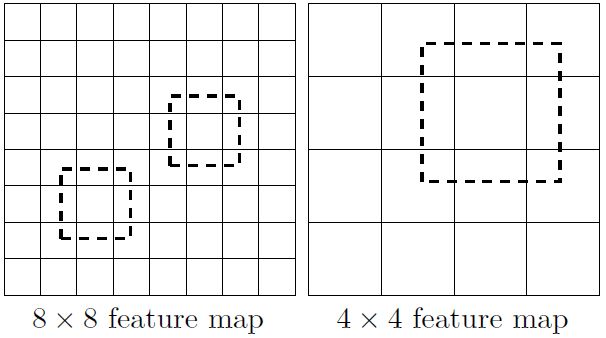
2)与YOLO最后采用全连接不同,SSD最后直接使用卷积来提取检测结果。
3)借鉴了Fast RCNN中的方法,取多个不同高宽比的Anchor,而不像YOLO只取两个。
SSD预测流程
预测流程图如下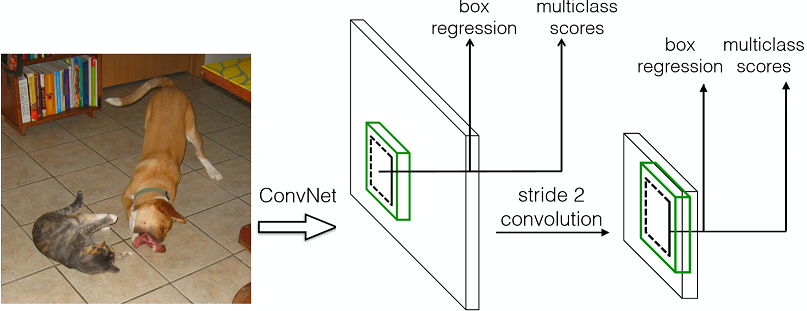
从上面可以看到,网络经过了两次特征提取,分别预测了两次不同框的分类和定位。
更详细的流程如下,网络运行过程中,各个阶段取大小不一的特征图进行目标检测,得到众多目标预测,最后综合通过NMS保留最终的预测框。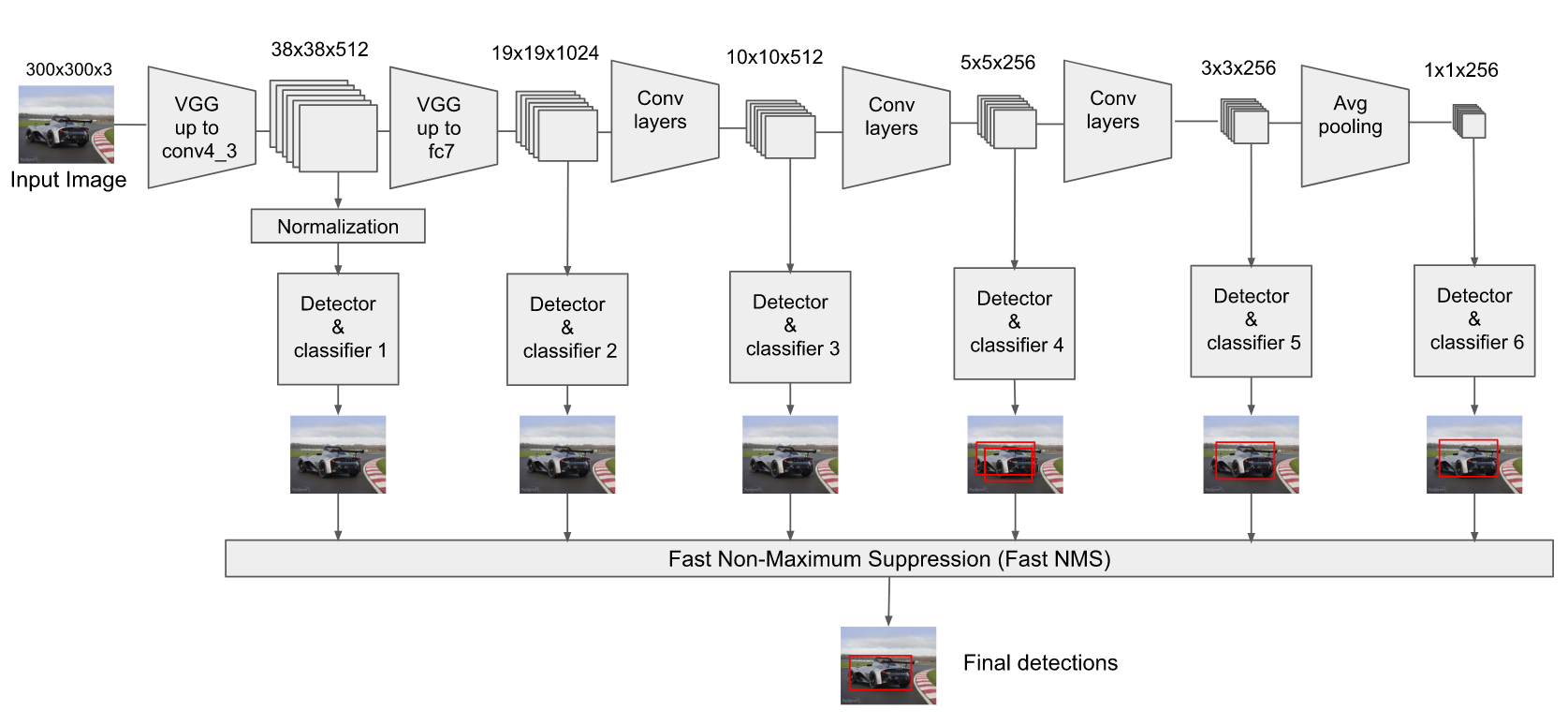
我们来看其中一个特征提取分支(大小5*5*256)的运行流程: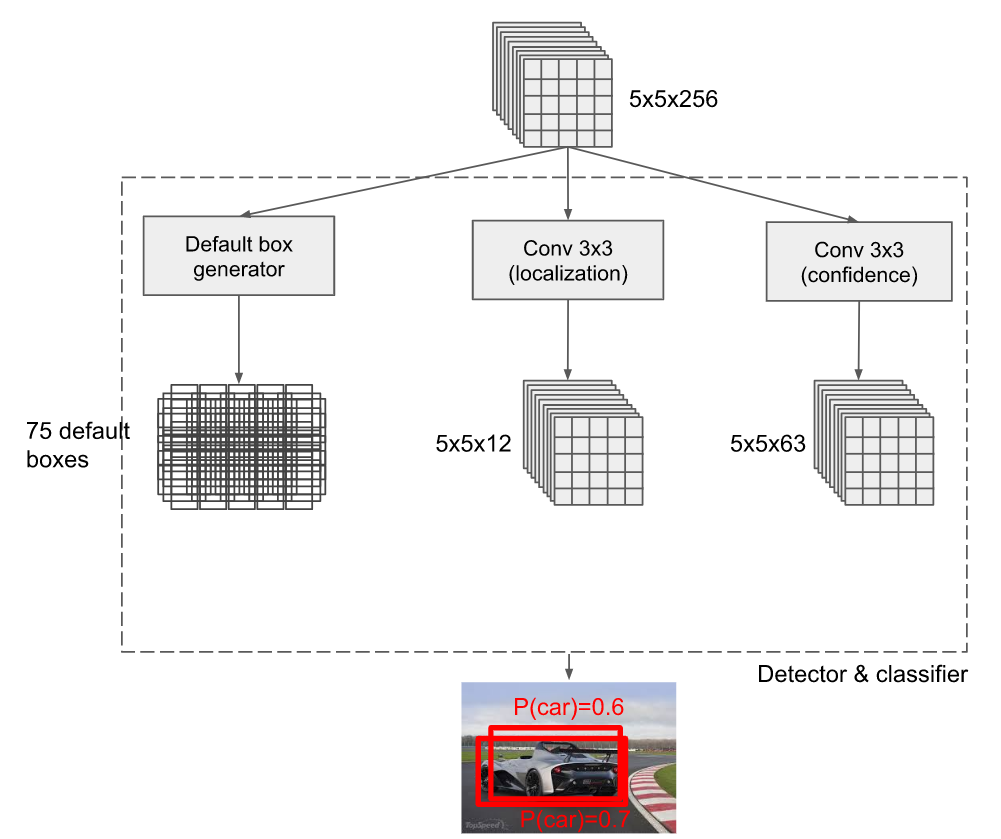
5*5*256的特征图会进行3部分计算:
1)产生Anchor box们,这里称作default box,上图中每个网格生成3个,一共生成75个
2)使用12个通道的3*3的卷积核对其进行卷积(padding=Same),得到5*5*12的定位预测结果
3)使用63个通道的3*3的卷积核对其进行卷积(padding=Same),得到5*5*63的分类预测结果
如何理解上面2),3)输出的预测结果呢?为什么定位预测是12维数据而分类预测时63维数据?见下图——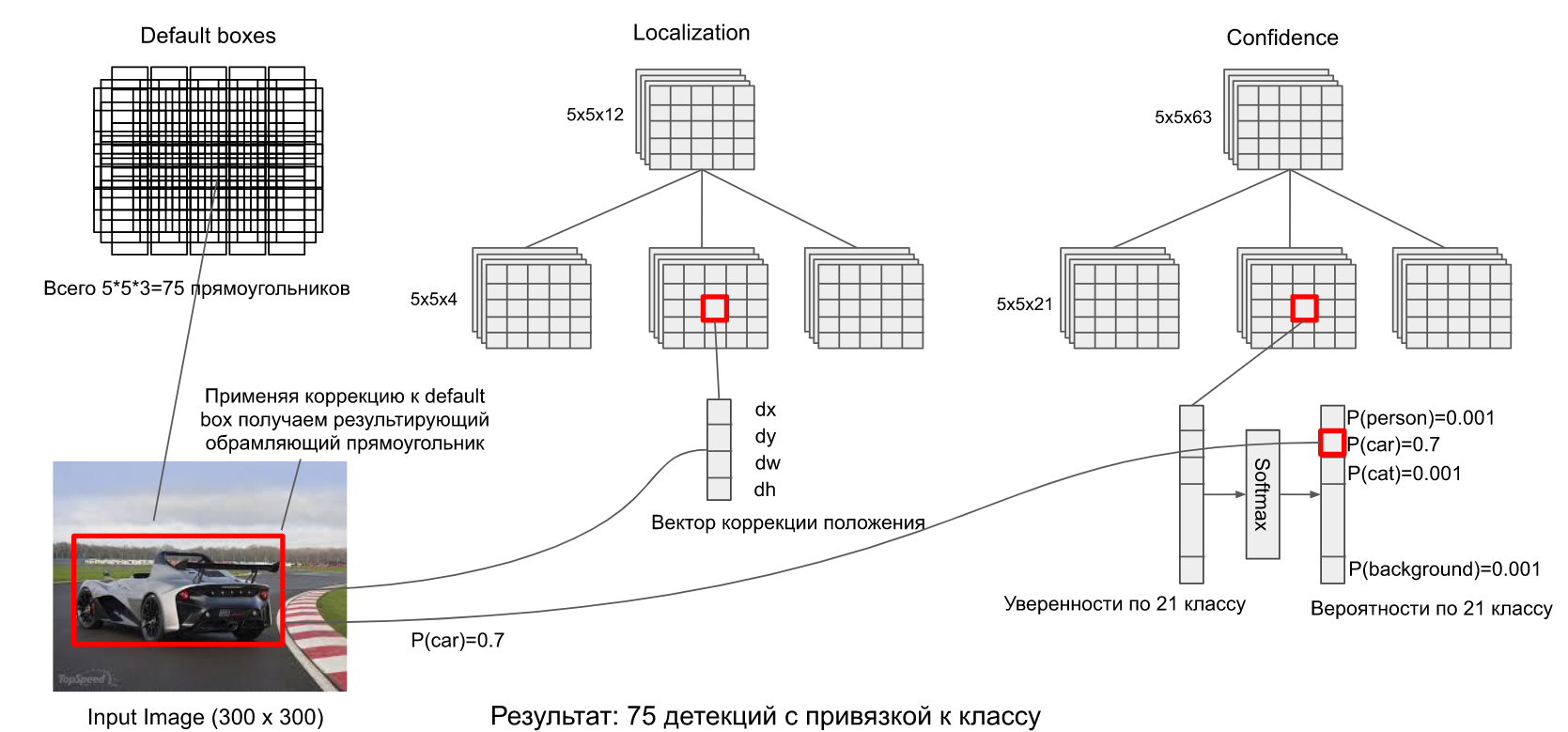
对于12维的定位数据来说,首先,因为每个网格定义了三个default box,所以数据应该分成3份,也就是每个default box有4个数据,就是我们要的定位数据:中心x坐标,中心y坐标,框宽,框高
对于63维的定位数据来说,同理分成3份,也就是每个default box有21个数据,也就是21个分类(其中包括1个“背景”类)。当然经过softmax函数之后可以输出概率值。
75个default box会有75种检测结果,也就是说每个box会有一个25维的数据(4个定位数据,21个分类概率数据)。使用NMS的方法(此文有详解)进行框保留。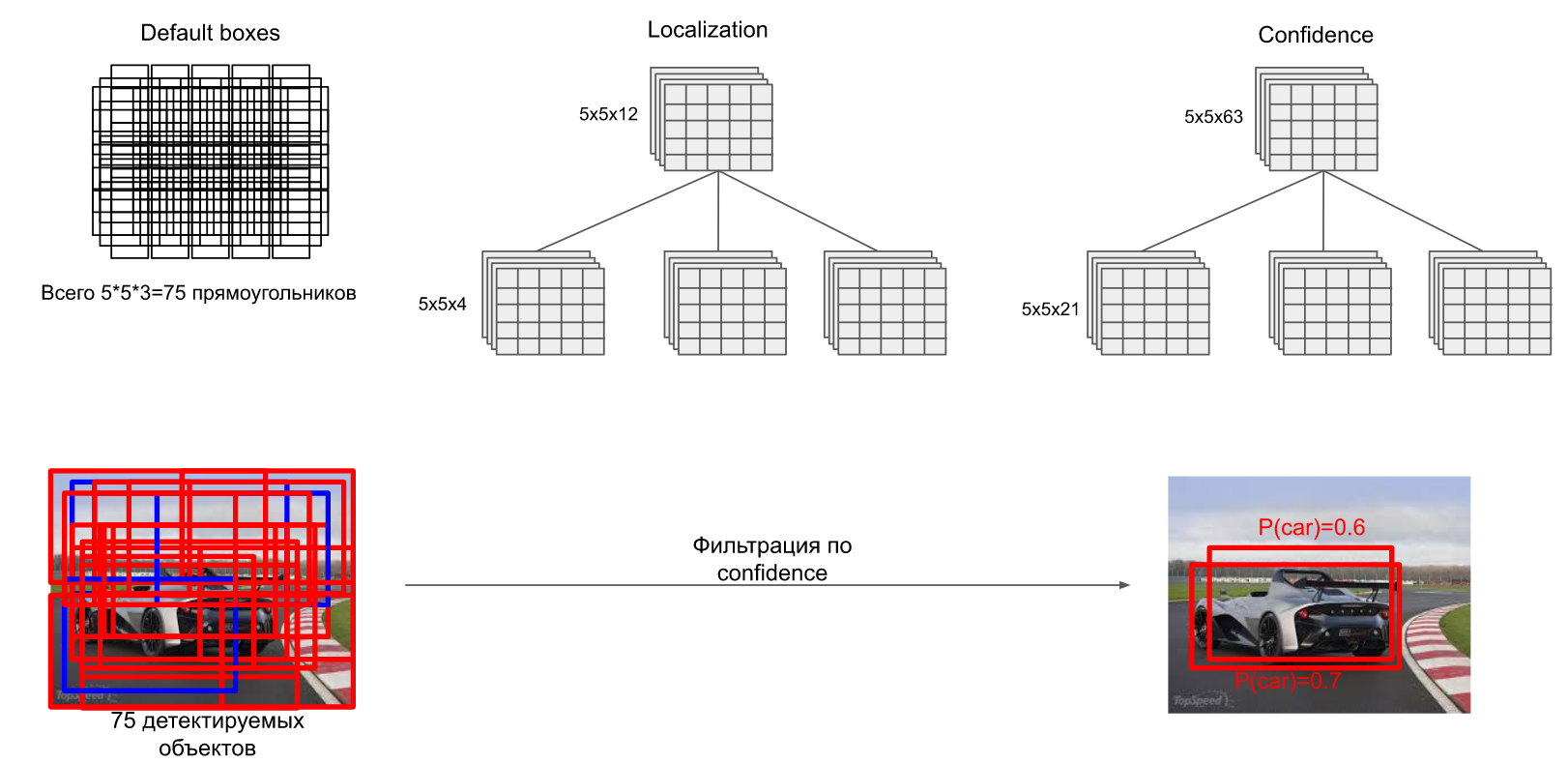
(其实上图我并不理解为什么会输出两个概率不一样且IOU如此高的Car框,我理解只要保留0.7的那个就好了)
总之,所有这样的特征提取分支输出的预测框会综合,再次使用NMS得出最终的预测结果
SSD的训练
类似于YOLO的训练
首先预训练CNN,然后进行迁移学习,也就是接入各特征提取分支构成新的网络。对这个新网络进行训练,原始数据是已经标注好实例分割的图片。
图片输入网络中,到达每一处S*S特征图,开始准备训练样本:将图片分割为S*S的网格,每一个网格有多个(比如3个,6个,9个) default box。与YOLO不同的是,SSD并不要求ground truth的中心落入某个网格就赋予该网格的default box正样本的机会,而是只要找到与ground truth的IOU最大的default box,就认为该default box为正样本;
不过其它的default box还有机会,如果一个default box与某个ground truth的IOU大于阈值(比如0.5),那么这个default box也被认为是正样本。这样的话,就允许一个ground truth与多个default box(最大IOU,次大IOU,…)匹配,比如同一个网格里的多个default box就很有可能大都被选中为正样本。
不过为了防止上一个条件被滥用,还有一个约束条件:不允许一个default box与多个ground truth匹配(比如当原始图片中有两个物体很小且紧靠着时)。这样做在逻辑上也是合理的,因为一个default box不能有多个label
剩下落选的default box就作为负样本。当然这里仍然采用hard negative mining,对负样本进行抽样,抽样时按照置信度误差(预测背景的置信度越小,误差越大)进行降序排列,选取误差的较大的top-k作为训练的负样本,以保证正负样本比例接近1:3
损失函数
损失函数为: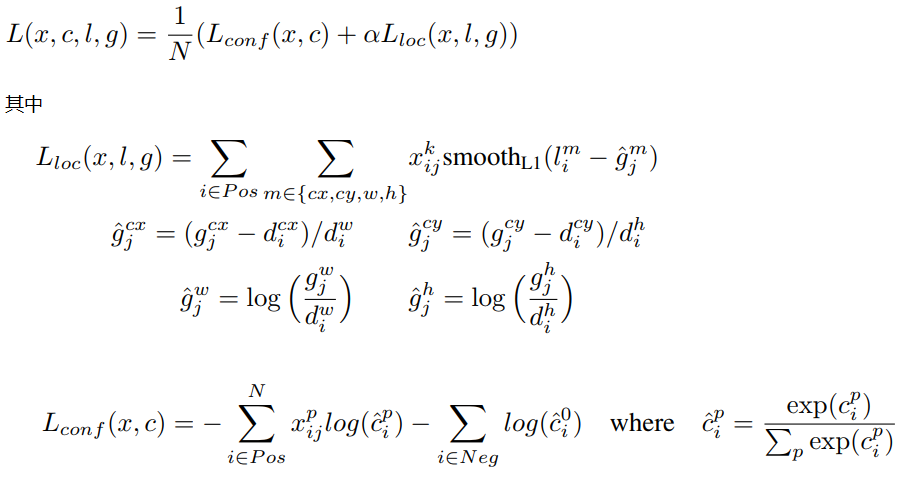
其中为先验的正样本数量
, 当
表示第i个default box与第j个ground truth匹配,并且ground truth的类别为p,对于没有匹配的,自然就是被删除的框,这时候
c为类别置信度预测值,l为先验框的所对应边界框的位置预测值,而g是ground truth的位置参数。
位置误差采用Smooth L1 loss,置信度误差采用softmax loss
为什么选择Smooth L1呢?因为当它处于[-1,1]之间时,梯度下降相当于L2,比较缓慢,不至于在最优值左右来回震荡;当它处于[−∞,-1],[1,+∞],梯度下降同L1,避免了L2的梯度爆炸: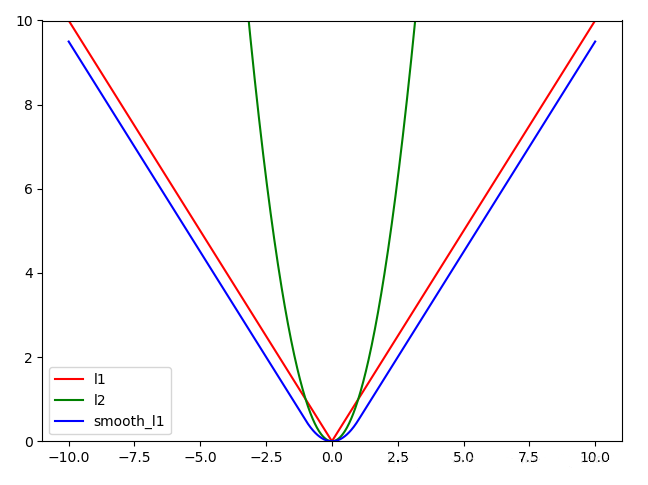
以上。