把大矩阵拆解为一个个小矩阵,把一个小矩阵当做一个元素,那么大矩阵就看起来不那么大了
两个大矩阵的相乘,就变成了两个不那么大的矩阵相乘, 所得矩阵中的每一个元素,仍然来自相乘矩阵的某一行和某一列的乘法求和, 只不过这里的”乘法”变成了小矩阵之间的矩阵乘法。
如下图: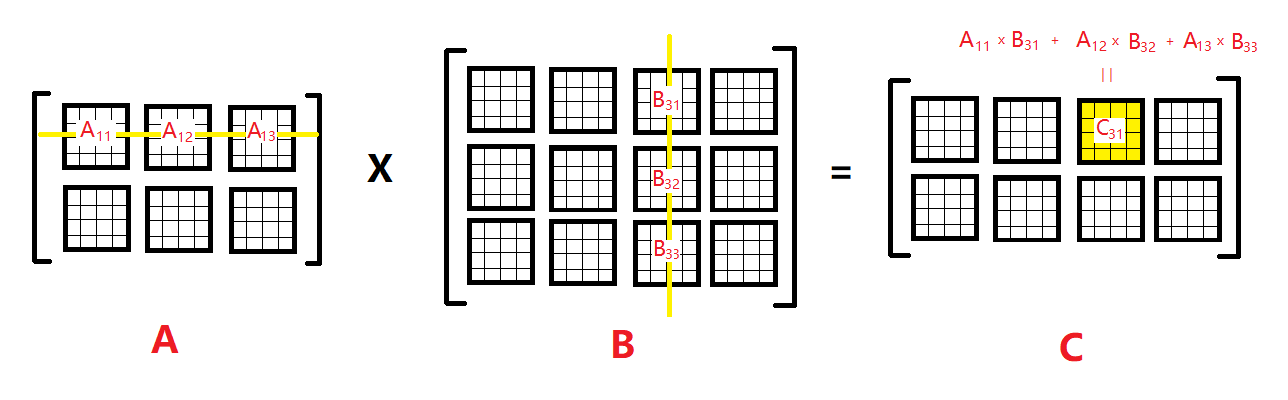
基于以上的矩阵分解方法, CUDA对大矩阵相乘问题,有了解决方案。
(未完待续)
1 | #include <iostream> |
把大矩阵拆解为一个个小矩阵,把一个小矩阵当做一个元素,那么大矩阵就看起来不那么大了
两个大矩阵的相乘,就变成了两个不那么大的矩阵相乘, 所得矩阵中的每一个元素,仍然来自相乘矩阵的某一行和某一列的乘法求和, 只不过这里的”乘法”变成了小矩阵之间的矩阵乘法。
如下图:
基于以上的矩阵分解方法, CUDA对大矩阵相乘问题,有了解决方案。
(未完待续)
1 | #include <iostream> |