CUDA里的shared memory是block级别的,所以两件事需要keep in mind:
1)当你allocate shared memory的时候,你其实在每个block里面都创建了一份同样大小却互相独立的share memory
2)当你进行__syncthreads()操作的时候,你只能保证此block里的thread在同步,此block里的shared memory在同步
这两个点在影响着shared memory使用的性能
关于shared memory的使用,直接看例子。
需求1: 两个向量元素两两相乘1
2
3
4Input: { 0, 1, 2, 3, 4, 5, 6, 7 }
{ 2, 17, 9, 21, 16, 39, 11, 28 }
Algorithm: 0*2, 1*17, 2*9, 3*21, 4*16, 5*39, 6*11, 7*28
Output: { 0, 17, 18, 63, 64, 195, 66, 196 }
解法: 不需要用shared memory,因为它是直通的1
2
3
4
5
6
7
8
9
10
11
12__global__ void myKernel(int *inArray1, int *inArray2, int *outArray){
const int tid = blockDim.x * blockIdx.x + threadIdx.x;
//每个thread负责一个元素,直通输出
outArray[tid] = inArray1[tid] * inArray2[tid];
}
int main(){
...
dim3 grid(2,1,1),block(4,1,1);
myKernel<<<grid,block>>>(inArray1, inArray2, outArray);
...
}

需求2: 向量元素与它左边元素相乘,并保存到原向量1
2
3Input: { 0, 1, 2, 3, 4, 5, 6, 7 }
Algorithm: 0, 1*0, 2*1, 3*2, 4*3, 5*4, 6*5, 7*6
Output: { 0, 1, 2, 6, 12, 20, 30, 42 }
错误解法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15__global__ void myKernel(int *array)
{
extern __shared__ int sharedMemory[8];
const int tid = blockDim.x * blockIdx.x + threadIdx.x;
sharedMemory[tid] = array[tid];
__syncthreads();
array[tid] = tid==0 ? array[tid] : array[tid] * sharedMemory[tid-1];
}
int main(){
...
dim3 grid(2,1,1), block(4,1,1);
myKernel<<<grid, block>>>(array);
...
}
之所以错误,是因为__syncthreads()只是完成了此block中的thread的同步,却不能保证跨block的thread同步,如下图。
每个block里发生的过程:复制数据到sharedMemory -> __syncthreads() -> 计算 。 具体来说,左右黄色和绿色分别代表一个block里的过程: sharedMemory在每个block里各有一份,首先将向量copy到sharedMemory中,各block只copy了一部分;接着使用__syncthreads()进行block内的同步; 最后利用准备好的数据进行计算。 如果两个block互不依赖,那么接下来的计算是没有冲突的。然而4虽然属于右block,但计算时却需要从左block中的shared memory拿数据,所以右block的的计算启动必须在左block的__syncthreads()完成之后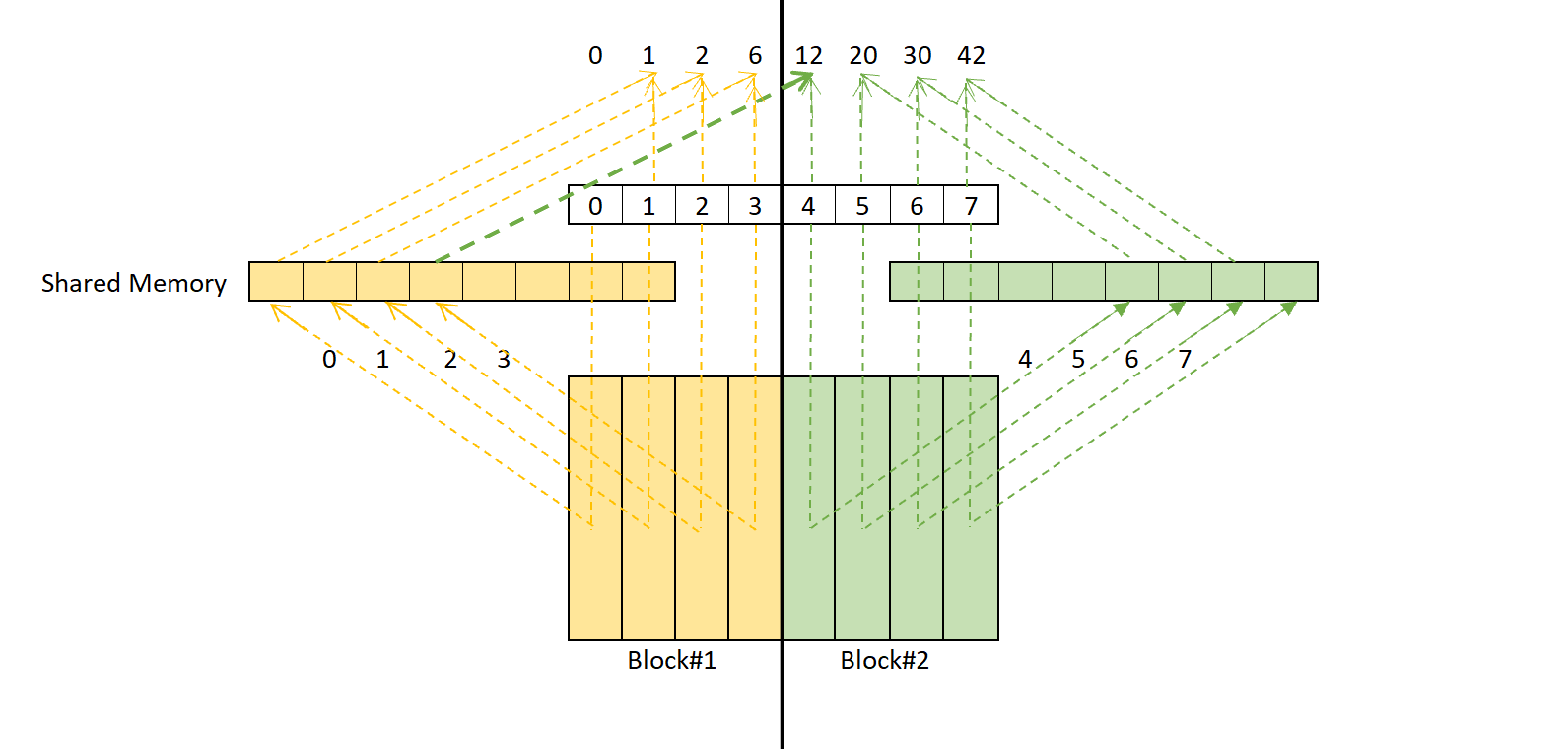
如何避免此问题?
1)使得向量在一个block里就好
正确修改1:1
2
3dim3 grid(2,1,1), block(4,1,1);
改为
dim3 grid(1,1,1), block(8,1,1);
2)多准备一份数据供本block供计算
正确修改2:1
2
3
4sharedMemory[tid] = array[tid];
改为:
sharedMemory[tid] = array[tid];
if(tid>0) sharedMemory[tid-1] = array[tid-1];
需求3:计算灰度图像的直方图1
2
3
4
5
6
7
8
9
10
11Input:
image = { 0, 255, 3, 2, 89, 3, 207, 46, 113, 3, 67, 3, ... }
range = [0,255]
Output:
Hist[0] = 2
Hist[1] = 5
Hist[2] = 67
Hist[3] = 32
...
Hist[255] = 45
解决: 可以直通,不使用shared memory1
2
3
4
5
6
7
8
9
10
11
12
13
14__global__ void createHist(uchar* img, const unsigned int imgSize, unsigned int* hist){
const unsigned int tid = blockDim.x * blockIdx.x + threadIdx.x;
if(tid >= imgSize) return;
const uchar pixelVal = img[tid];
atomicAdd(&(hist[pixelVal]),1); //hist已经初始化为全0向量
}
int main(){
...
// threadsPerBlock * blocksPerGrid > imgSize
dim3 block(threadsPerBlock,1,1),grid(blocksPerGrid,1,1);
createHist<<<grid,block>>>(img, imgSize, hist);
...
}
但是从0开始,一共有imgSize个thread分别对全局的device memory hist进行了写操作。
能不能使用shared memory来统计每个1
2
3
4
5
6
7
8
9
10
11
12
13__global__ void createHist(uchar* img, const unsigned int imgSize, unsigned int* hist)
{
const unsigned int tid = blockDim.x * blockIdx.x + threadIdx.x;
if(tid >= imgSize) return;
__shared__ int sharedMemory[256];
sharedMemory[threadIdx.x] = 0;
__syncthreads();
atomicAdd(&sharedMemory[img[tid]], 1);
__syncthreads();
atomicAdd(&(hist[threadIdx.x]), sharedMemory[threadIdx.x]);
}