论文在此
YOLO这个名字完整体现了算法的精髓:You Only Look Once
它与RCNN系列算法不同。RCNN系列算法(RCNN/Fast RCNN/Faster RCNN)是经过了两次检测,第一次是获取proposal box,第二次才是图像预测。YOLO算法通过回归来完成物体检测,期间使用了统一的网络来完成物体识别和框定位。
YOLO运行流程
它的推理流程图如下:
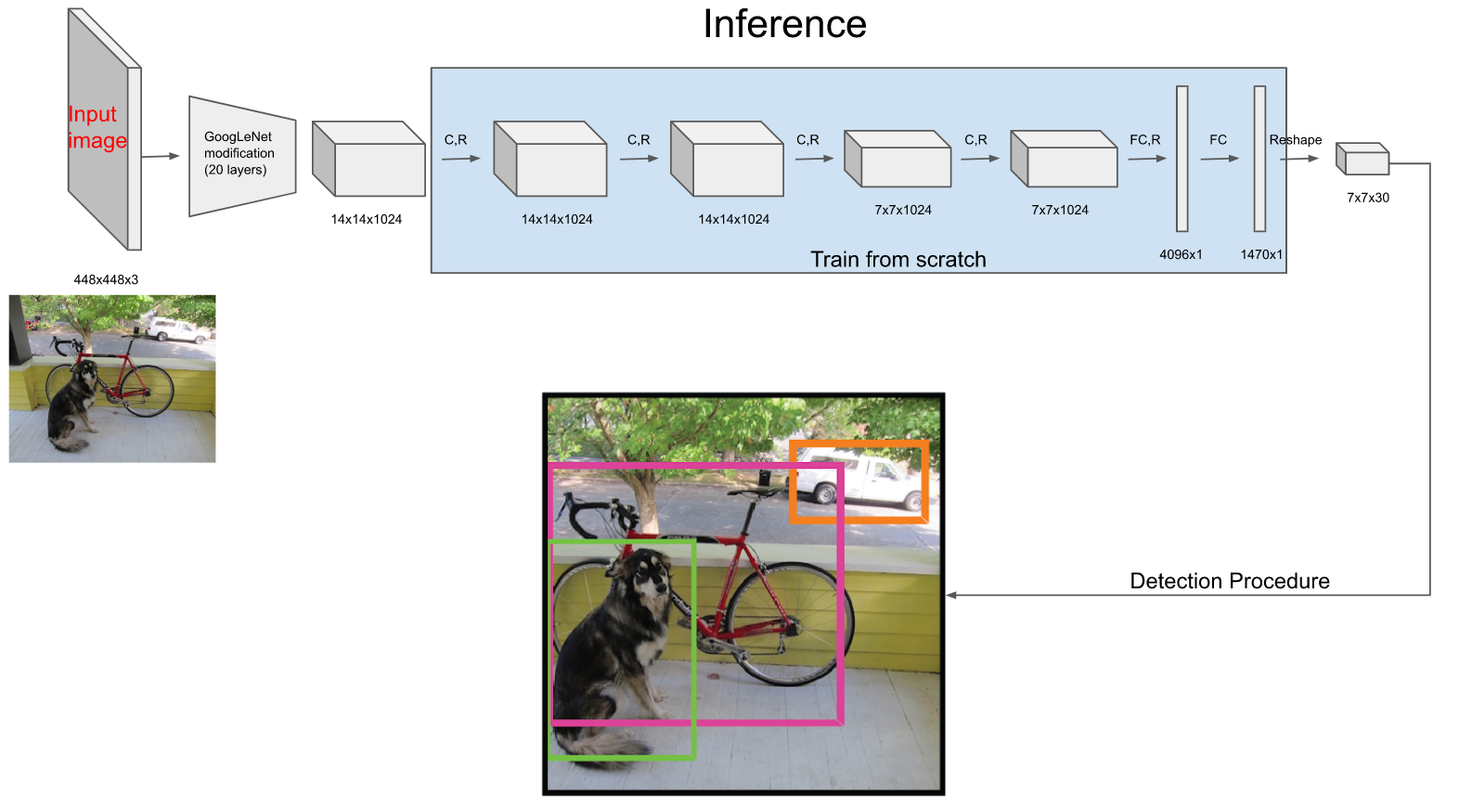
经过网络之后输出为7*7*30的特征图,也就是有49个30维向量。 这个特征图意味着什么呢? 意味着可以认为将原图划分为7*7的网格,每一个网格对应一个30维的向量。这么说不太严谨,容易误导为:7*7的网格图中的每一个网格的图像信息严格对应7*7*30特征图的每一个向量。要理解这一点先要理解感受野:
如下图,经过卷积得到的3*3的矩阵的元素映射到原矩阵的感受野是2,而并非4/3,且感受野之间是互相重叠的
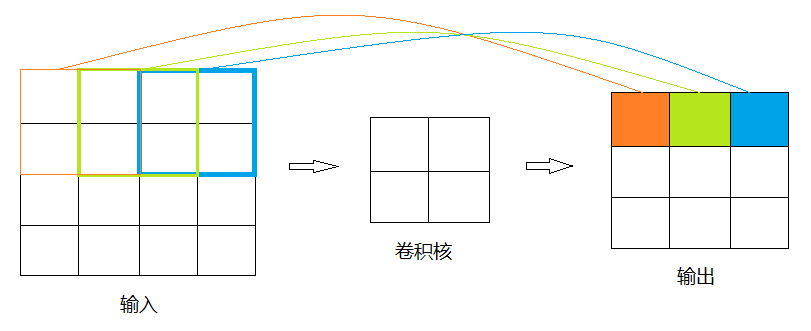
(更多感受野的理解见此文)
所以说,YOLO流程图里的一个30维向量包含的不仅仅是一个网格的信息,它包含了含有该网格的更大图像范围的信息,这个知识点有利于理解接下来要讲的为什么30维向量里能包含已经超出网格之外的Anchor信息。
30维向量信息解析
30维数据的前5维,是以该网格为中心的第1个Anchor的5个信息:框的x坐标,框的y坐标,框的宽,框的高,框中有物体的置信度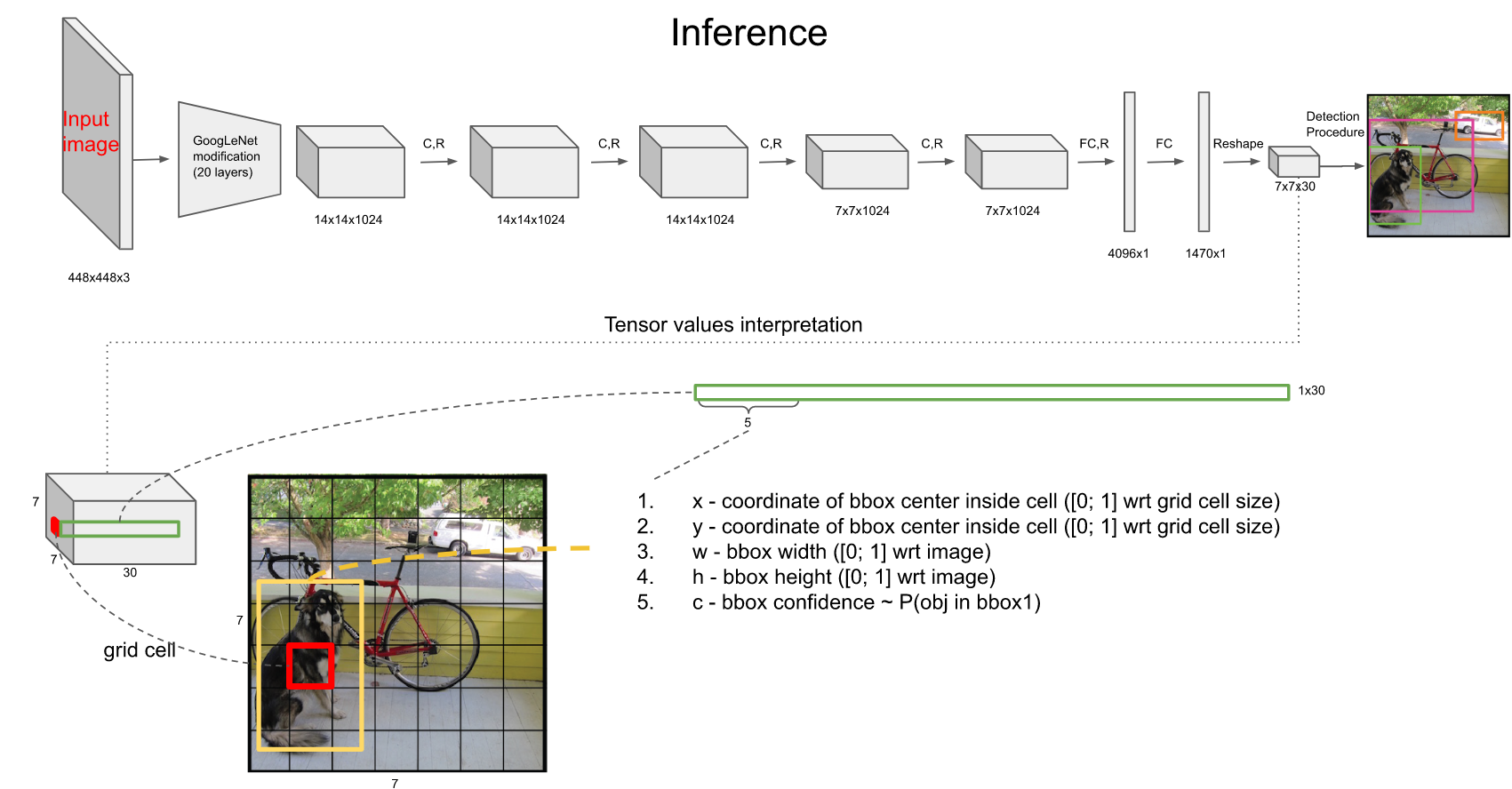
紧接着的5维,是以该网格为中心的第2个Anchor的5个同上的信息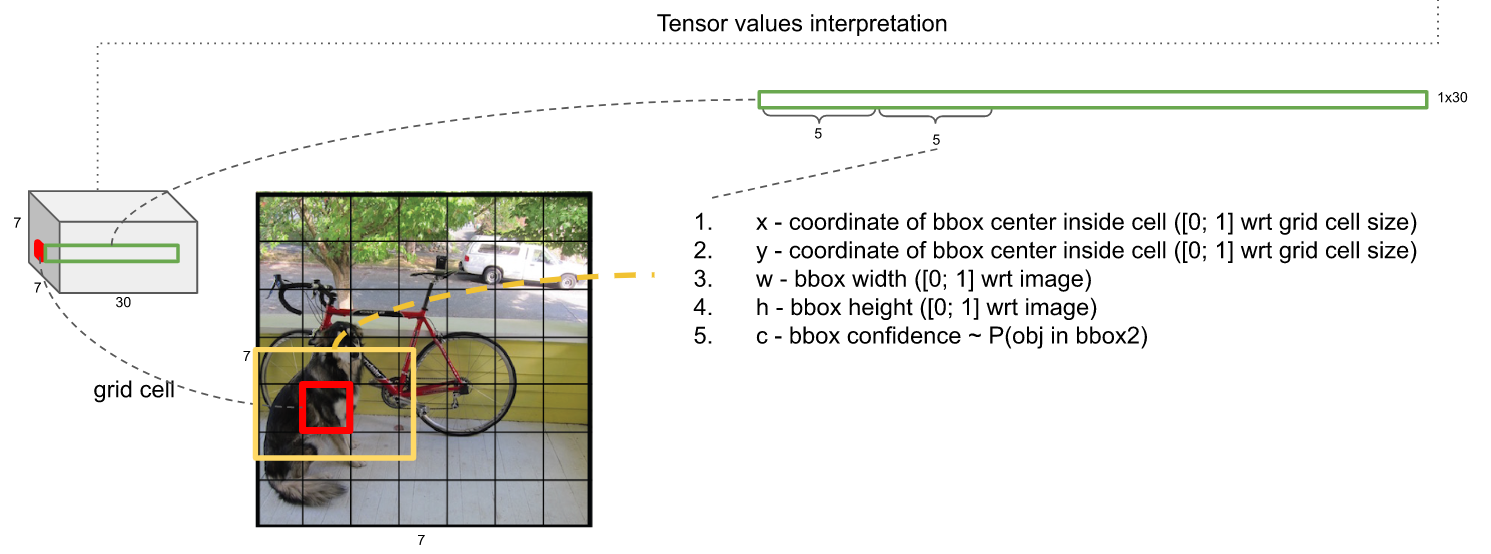
之后的20维中的任何1维度,是该网格为中心的2个Anchor里的图像为某一个类别的打分,这样对每个网格(它的2个Anchor)得到20个打分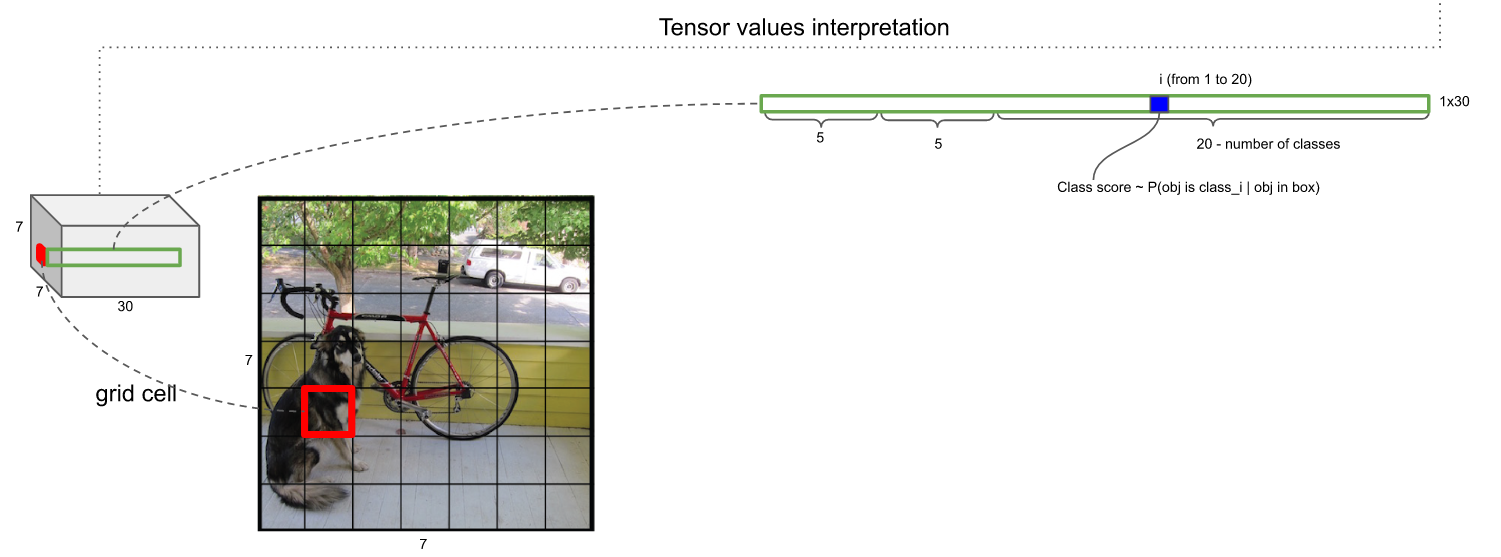
如何获取某个Anchor是某个类的概率呢?——将上述的打分乘以该Anchor有物体的置信度即可,那么每一个Anchor就相当于有一个20维的概率向量: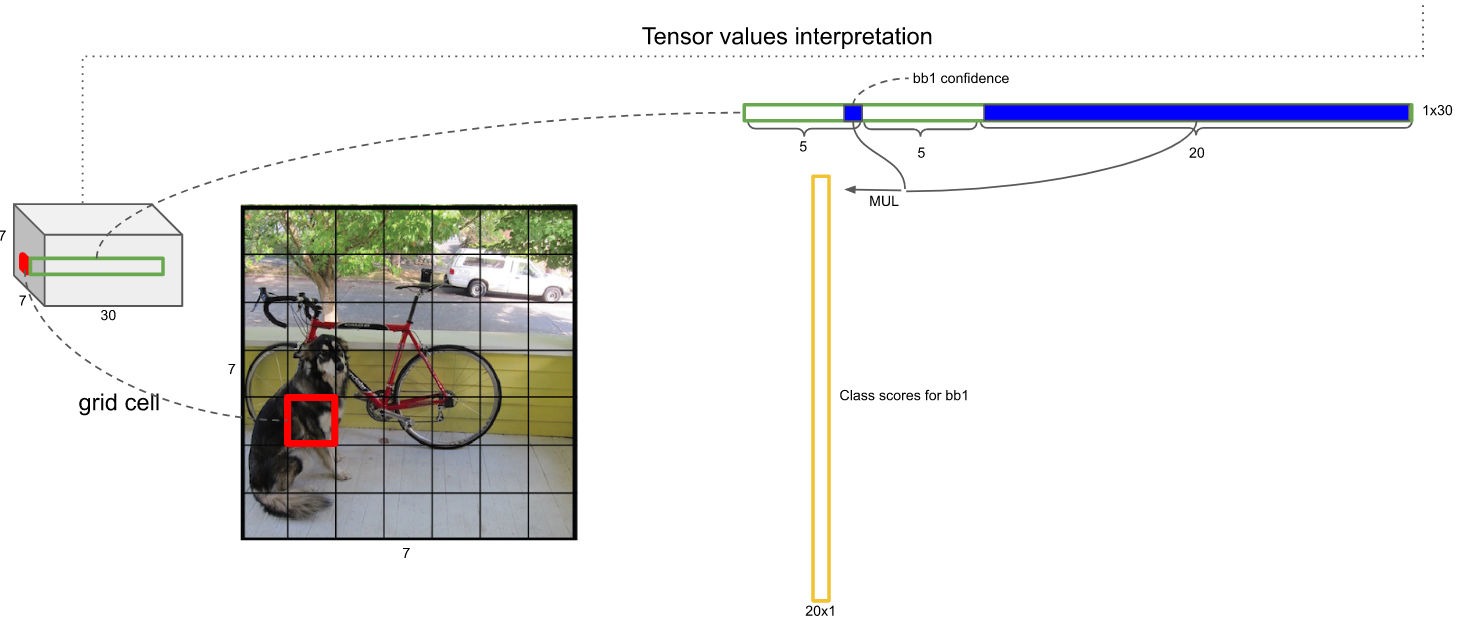
由此,每个网格两个Anchor,也就是有2个20维概率向量,7*7个网格一共有98个20维向量: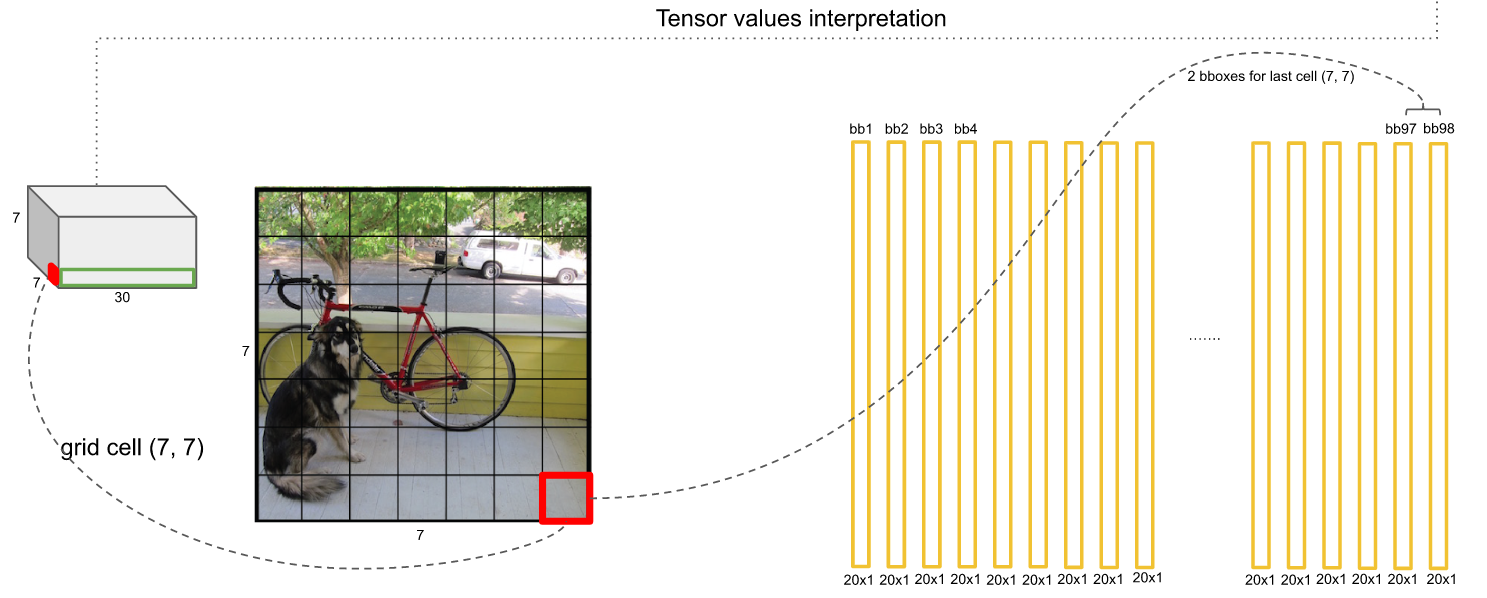
Box预测和保留
对于每一个种类的概率,比如Dog,我们将所有98个框按照预测概率从高到低排序(为方便计算,排序前可以剔除极小概率的框,也就是把它们的概率置为0),然后通过非极大抑制NMS方法,继续剔除多余的框: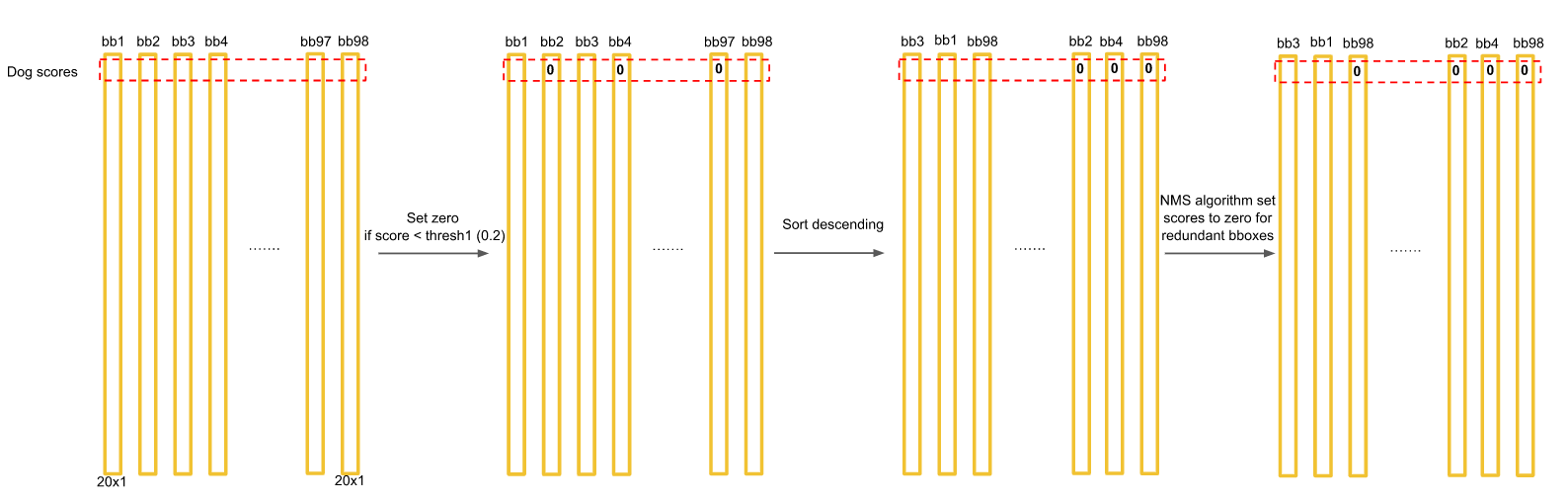
NMS方法在这里如何运行呢?首先因为经过了排序,所以第一个框是概率最大的框(下图橘色)。然后继续扫描下一个框跟第一个框,看是否IOU大于0.5: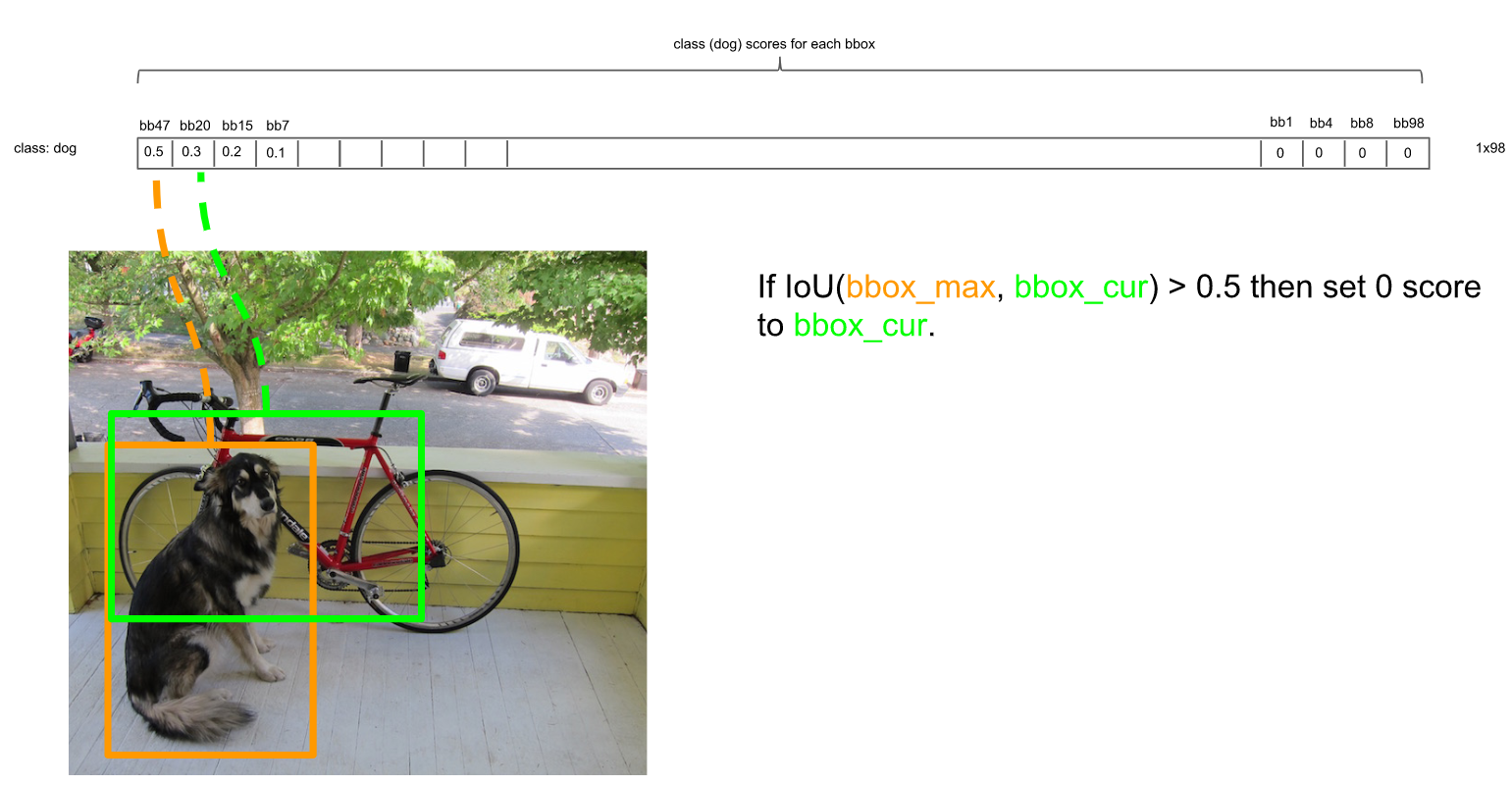
的确IOU大于0.5,那么第二个框是多余的,将它剔除:
继续扫描到第三个框,它与最大概率框的IOU小于0.5,需要保留: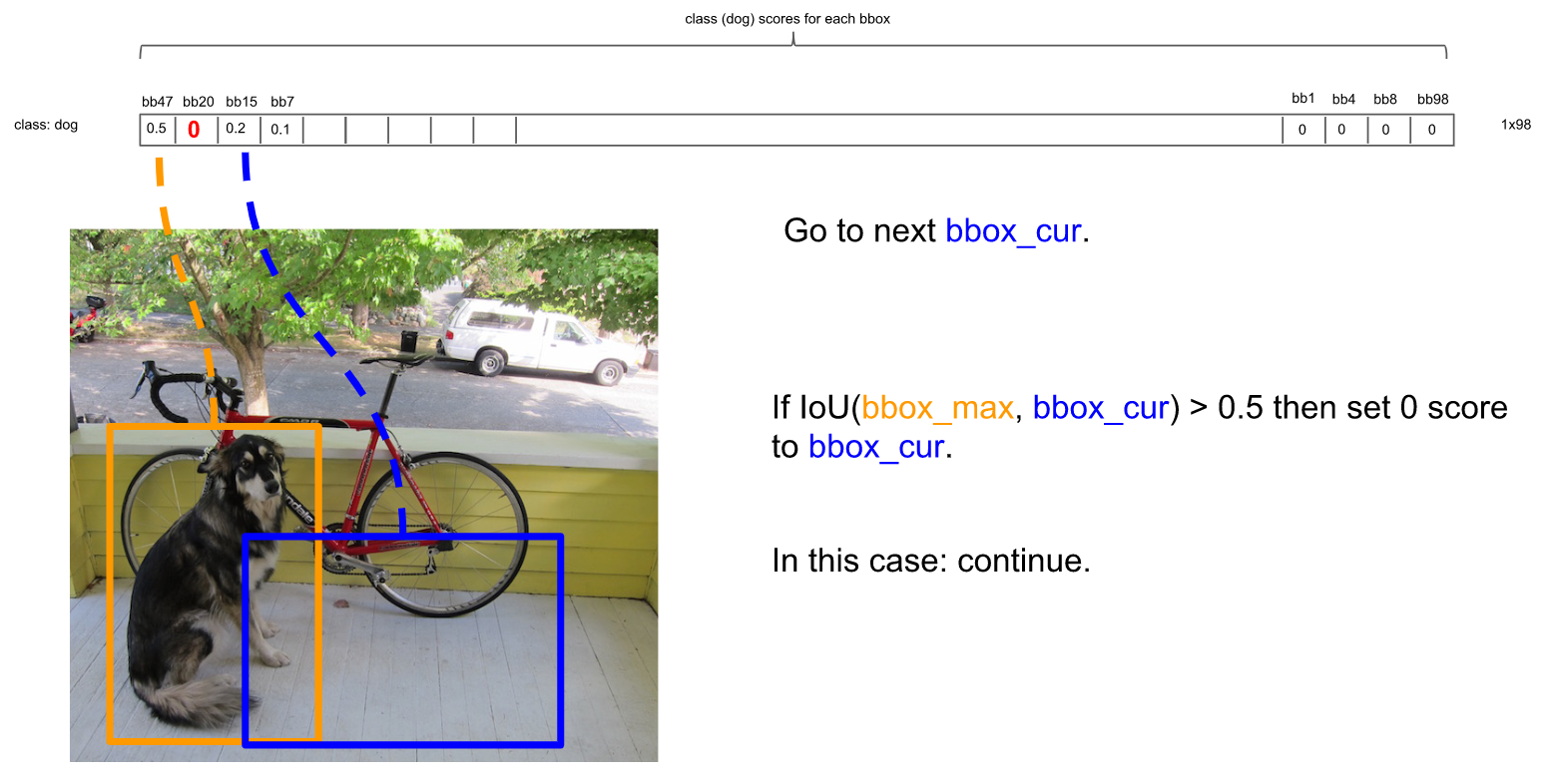
继续扫描到第四个框,同理需要保留:
继续扫描后面的框,直到所有框都与第一个框比较完毕。此时保留了不少框。
接下来,以次大概率的框(因为一开始排序过,它在顺序上也一定是保留框中最靠近上一轮的基础框的)为基础,将它后面的其它框于之比较。
如比较第4个框与之的IOU: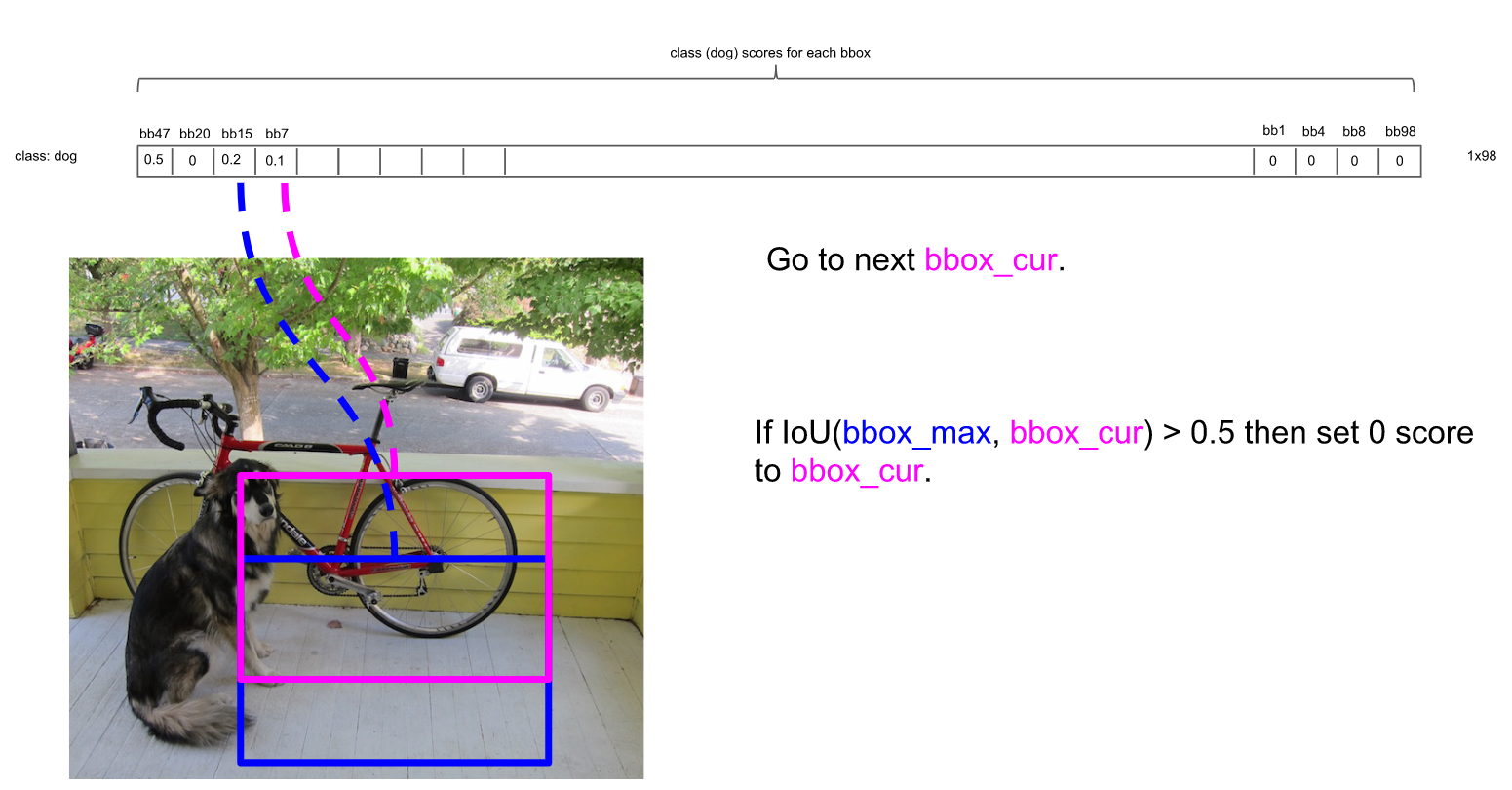
IOU大于0.5,所以可以剔除第4个框:
总之在经历了所有的扫描之后,对Dog类别只留下了两个框: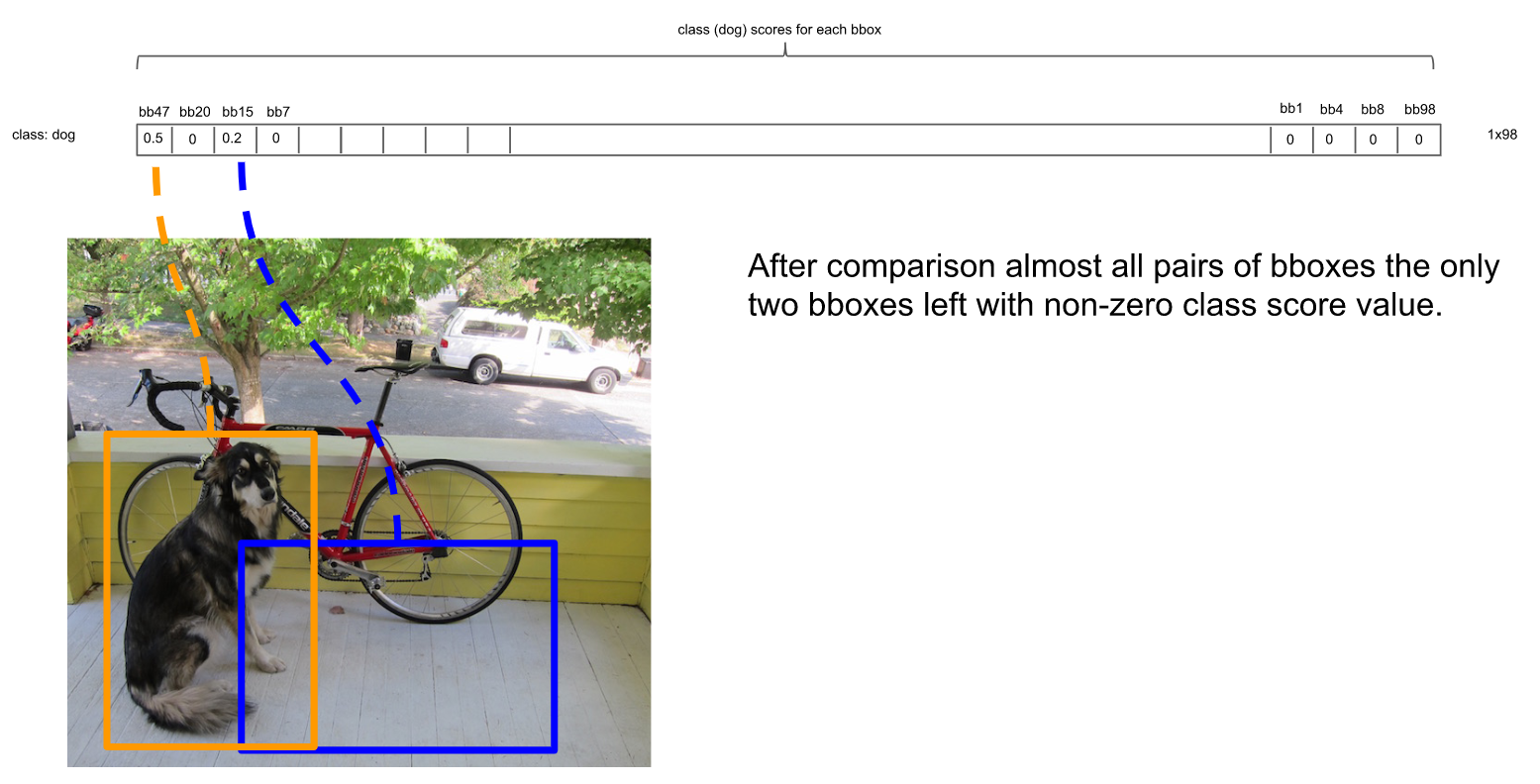
这时候,或许会有疑问:明显留下来的蓝色框,并非Dog,为什么要留下?因为对计算机来说,图片可能出现两只Dog,保留概率不为0的框是安全的。不过的确后续设置了一定的阈值(比如0.3)来删除掉概率太低的框,这里的蓝色框在最后并没有保留,因为它在20种类别里要么因为IOU不够而被删除,要么因为最后阈值不够而被剔除。
上面描述了对Dog种类进行的框选择。接下来,我们还要对其它19种类别分别进行上面的操作。最后进行纵向跨类的比较(为什么?因为上面就算保留了橘色框为最大概率的Dog框,但该框可能在Cat的类别也为概率最大且比Dog的概率更大,那么我们最终要判断该框为Cat而不是Dog)。判定流程和法则如下:
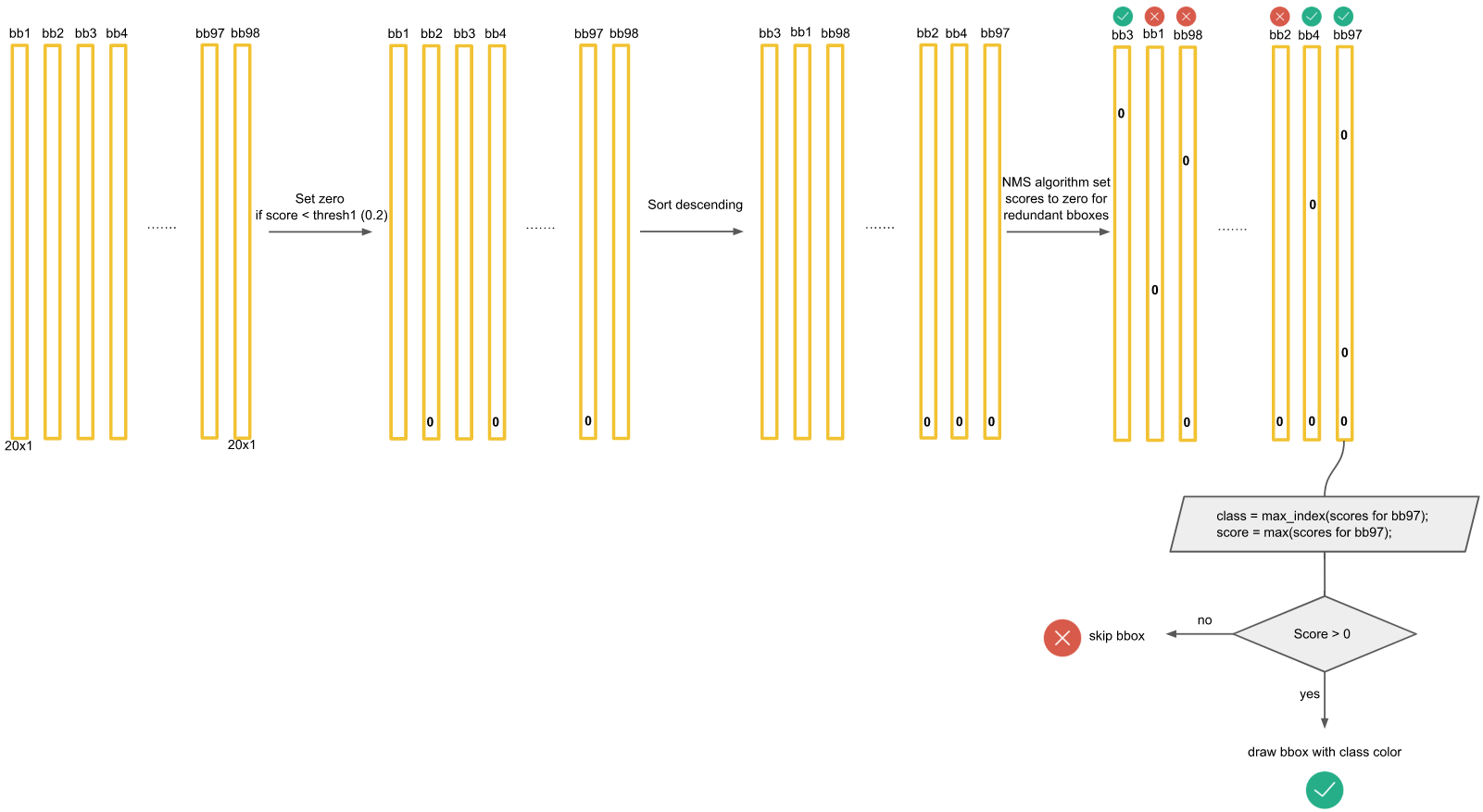
得到最后的结果: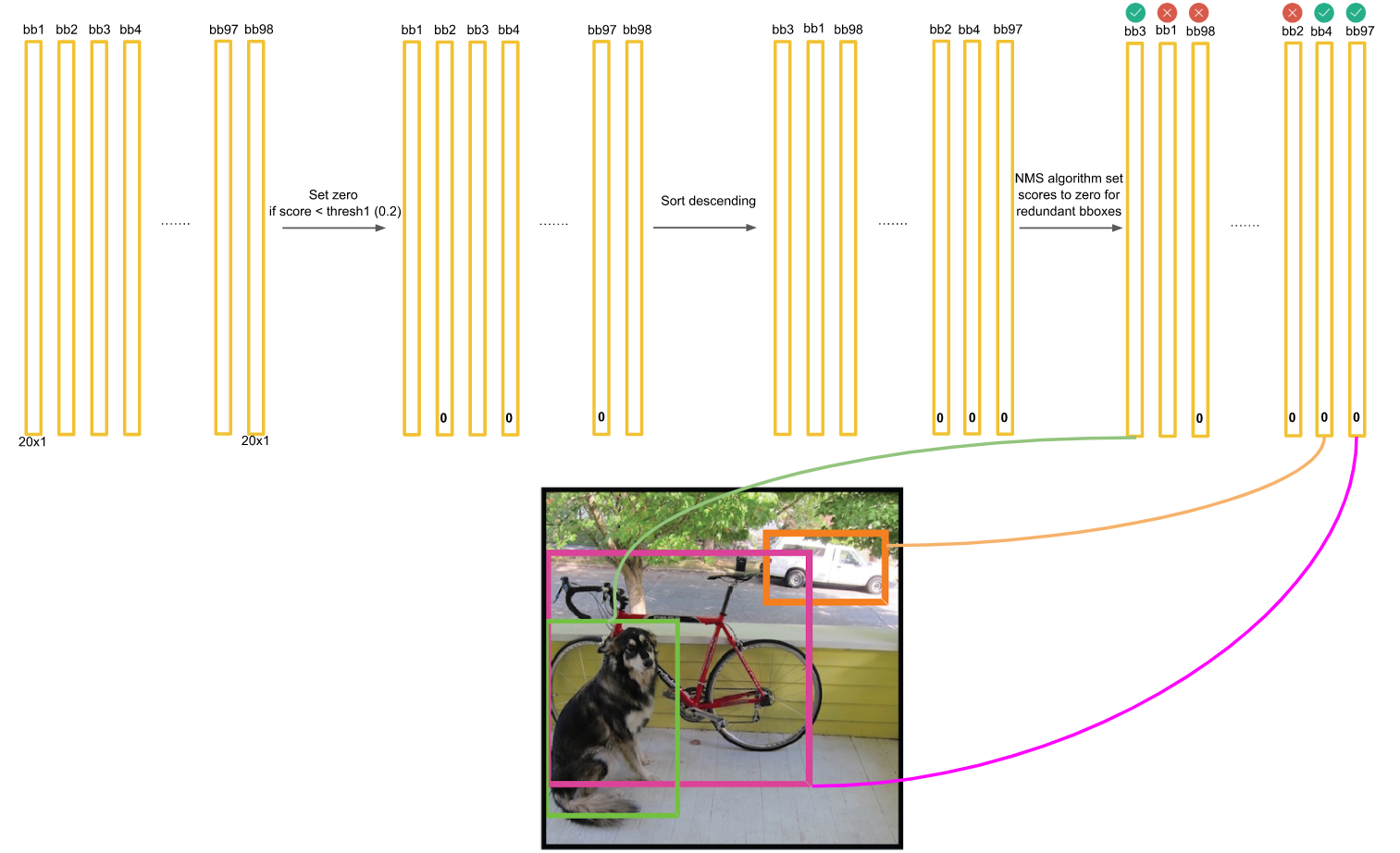
YOLO的训练
首先预训练,使用ImageNet数据库训练上面流程图中的GoogleNet Modification,使得该网络具有强大的物体识别能力。
然后进行迁移学习,也就是将上面预训练好的网络,接上后面需要进行图像分割的卷积核全连接网络,继续进行训练。这个阶段的训练流程如下:
首先,YOLO训练的原始数据是已经标注好实例分割的图片。图片输入YOLO网络中,首先分割为S*S的网格,每一个网格有2个Anchor。对每一个网格来说,只保留一个Anchor,通过标注框(ground truth)和Anchor的IOU取大的(且要大于0.5)来保留Anchor。这里有一种情况:如果相邻的两个网格的都各自有一个Anchor与标注框的IOU达到了0.5甚至他们的IOU完全一样,那么保留哪个Anchor呢?YOLO算法里,作者提出的方法是,只有ground truth的中心点落到了某个网格中,该网格对应的Anchor才有资格保留。保留下来的作为正样本,其它的作为背景类,为负样本。当然负样本可以采用hard negative mining,对负样本进行抽样,抽样时按照置信度误差(预测背景的置信度越小,误差越大)进行降序排列,选取误差的较大的top-k作为训练的负样本,使得正负样本比例不会失调(正负样本比例1:3比较合理)。
总之,只有部分网格中的部分Anchor保留下来了。保留下来的Anchor框可进一步进图像分类,框位置调整的预测,获取预测值。
损失函数
损失函数如下: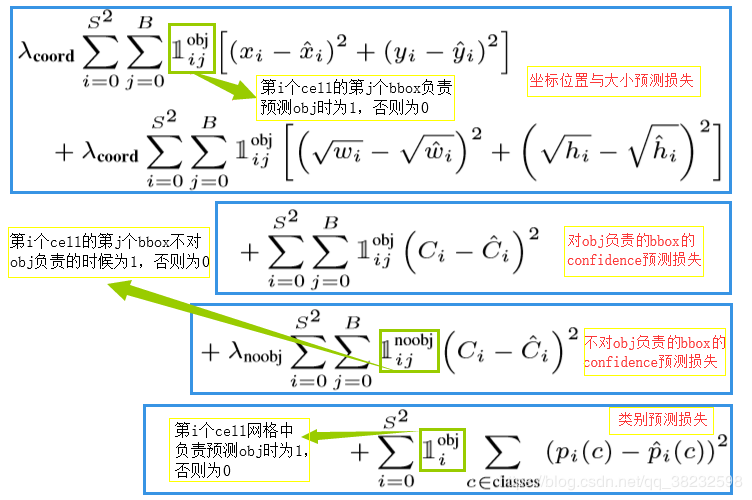
图中S为网格维度,B为Anchor个数,i为第i个网格,j为第j个Anchor。
上面讲过,在训练的时候,只有部分Anchor能入选,所以只有入选了才进入损失函数中。
在作者的文章中:
1)λcoord取5,因为需要重视坐标预测
2)λnoobj取0.5,因为大部分Anchor是没有入选的,积累了很多损失之后,不能给它大的系数
3)w和h之所以用来平方根,是因为在实际中,物体可能比框出它的框要小很多,那么物体实际的宽和高是要削减的。于是作者使用平方根来进行中和
以上。