首先我们看我们要实现的什么:
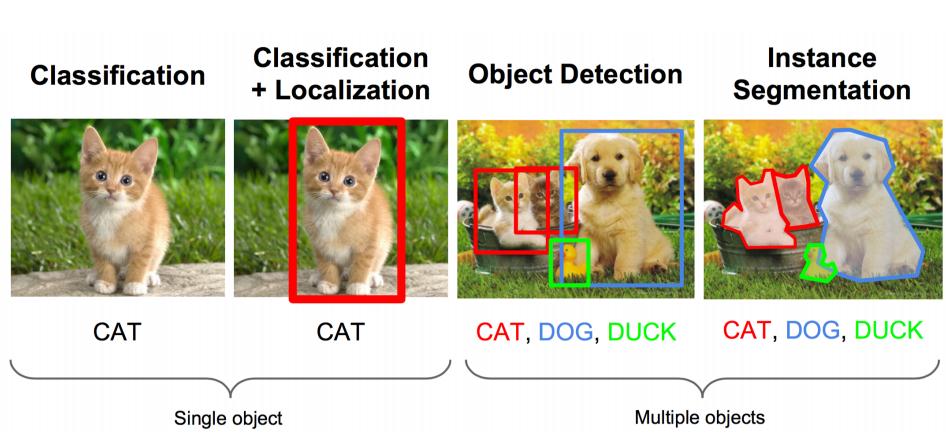
我们要实现图3的Object Detection.不仅需要将物体识别出来还需要画出它们的位置。我们知道将物体识别,通过CNN是可以实现的,那么这里关键的部分就是定位了。基于CNN和定位的思想,算法界出现了RCNN,即Region Convolution Neural Network. 之后,基于RCNN,相继出现了改进的算法:Fast RCNN, Faster RCNN, Mask RCNN.
本文将逐一讲解以上算法。
RCNN
论文在此
RCNN的模型如下:
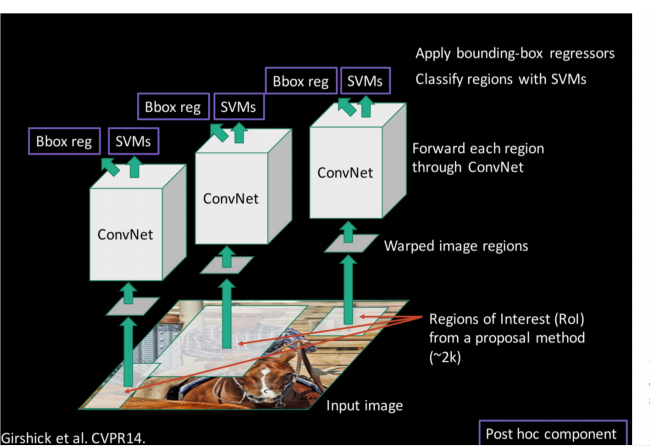
RCNN预测模型
它的预测流程是:
1)使用Selective Search方法选中proposal框
2)将选出来的proposal框们resize到固定大小,然后分别通过CNN(比如AlexNet)识别器。不过这不是完全的CNN网络,而是走到全连接之前获得了4096个特征就停止。
这是完整的CNN网络: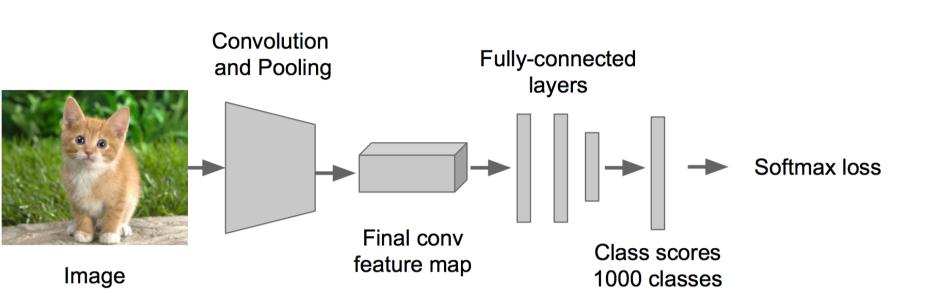
这是中间停止的: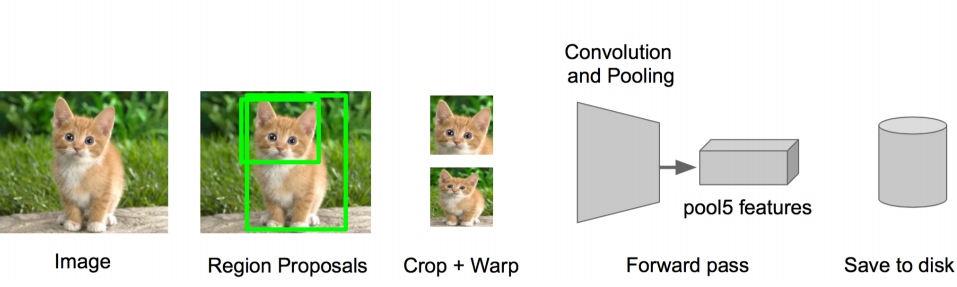
可以看到在第5个池化之后,我们已经获取了4096个特征。
如果图片一共有2000个proposal框,那么经过这一步骤之后我们得到了一个2000*4096的特征矩阵
3)将每个proposal框的4096个特征分别经过20个SVM二分类器(每个分类器有4096个系数)进行物体识别分类
这个过程可以用2000*4096的矩阵和4096*20的矩阵相乘来表示,求得一个2000*20的矩阵。这个矩阵每一行表示某个proposal框在是各种类别的打分(或者概率)。
4) 使用非极大抑制方法来去除无用的框。
所谓无用的框是因为2000个proposal框中其实只有很少的框是最终需要留下来的。这里的非极大抑制方法是保留(想象上面2000*20矩阵中的每一个元素)打分最高的框,同时与该框框重叠度(称作IOU)超过设定阈值(比如0.6)的框被删除。它的思想是抑制局部非最大的,保留局部极值

这种方法之所以有效是因为:首先打分最高的框是可能框得最合理的(因为我们相信CNN识别器的准确度),而与该框重叠度比较高的框很可能是框柱了该物体的很大一部分,却框偏了的。
可以思考一种实际情况:当图片里面有两只猫在不同的位置。这时候,在“猫”的这个分类下面,会有两个框被保留下来,因为尽管这两个框的打分有大有小,但是它们的IOU是远小于阈值(比如0.6)的。
另一种实际情况是:如果待识别的图片里面只有一只猫(虽然选出了很多个proposal框),而SVM分类器有猫、狗、鱼等20个类别。那么这些proposal框中会有非常多的框在任何分类下的打分都是非常低。如果根据非极大抑制方法,那么在“狗”这个分类下会保留至少一个框,这是不符合要求的。可见,非极大抑制还需要设置打分阈值,即不是所有局部极值都能保留,如果没有到达打分阈值,该类别下所有值都可能被删除。
5)将留下来的框,通过回归器来进行位置微调
每个类别会有4个被训练好的回归器,分别用来回归4个值:框的左上顶点的x坐标,y坐标,框的宽,框的高。每个类别都有,意思是比如猫有猫的框位置回归器4个,狗也有狗的4个。按类别分的思想是:系统认为框柱一只胖猫和一只很高的长颈鹿,用的框是不一样的。
至此一次目标检测就完成了。
三个模型的训练
在RCNN中有三个独立的部分:CNN识别器,SVM分类器,位置回归器。
CNN识别器的训练
这个CNN不是完全的CNN,而是做了fine-tuning。具体构建如下:
首先使用ImageNet数据进行训练或者找到一个现成的通用的CNN物体识别器,它有识别1000种物体的能力:
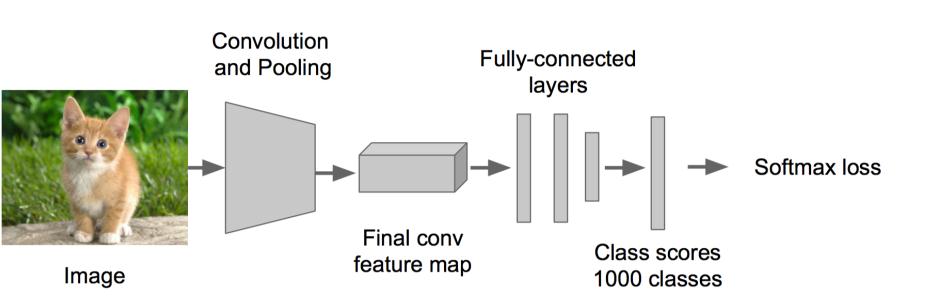
我们需要它是因为,它含有训练好的具有强大识别能力的参数。
接着做一个迁移学习网络。截掉softmax和改动了最后一个全连接层,且将最后一个全连接从4096*1000 更改为4096*21,再次训练这个新的21类识别器网络。这么做是为了利用1000类识别器已经训练好的强大参数作为初始值。
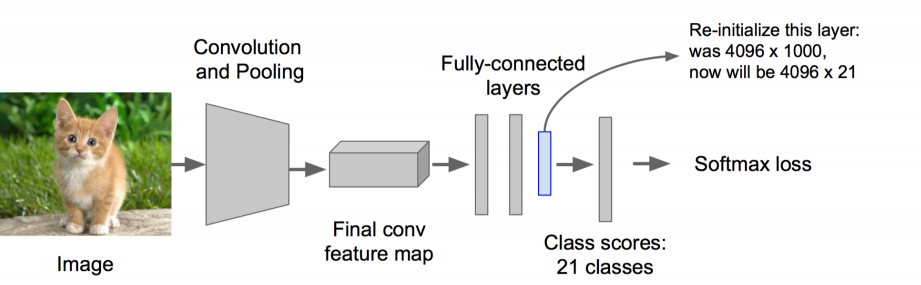
注意,训练该21类分类器时,使用的数据是用于目标检测的数据库,也就是人为标注了框,带有类别标签的图片。确切地说,是被框出来的那些图像。之所以如此,是因为我们终究需要它适应目标检测的图片,而不是ImageNet数据库里的广义图像。
不过等等,我们可以用一种类似数据增强的方法:使用selective search之后proposal框出来的图像,而不是作为label的框出来的图像。把与label框的IOU大于0.5的proposal框图像抠出来作为数据,把label作为它的label;把与label框的IOU小于0.5的proposal框图像抠出来作为数据,把“背景”作为它的label(这就是为什么有第21个类)。这样我们就充分利用了大量的selective search出来的图像。
值得一提的是,这里训练出来的21类识别器仍然没有被用到最后的预测网络中。因为我们要的不是它的21类预测能力,而是它在进行21类预测前所训练出来的提取特征的能力。我们用提取出来的特征(每个框是4096个特征),转而用SVM进行21类分类。因为RCNN的作者通过实验得出的结论是SVM的识别率高于全连接加softmax的输出。
SVM分类器的训练
正如上面所说,SVM分类器的数据来自于被中断的CNN输出,中断点是在全连接之前,第5个池化之后的4096个特征的输出。上面的预测过程中已经给出了图。
在训练过程中,SVM的数据来自于带框和label的数据。但是与上面CNN网络的训练不同的是,正向样本严格来自于label数据中框出的数据及其label,将它们输入CNN中,中途输出4096个特征,就是SVM的正向样本;而负向样本可以来自于selective search得到的且与label框的IOU小于0.3的proposal框。 当然这里会导致负样本远远大于正样本个数,可以通过hard negative mining来解决。 具体请自行搜索
位置回归器的训练
位置回归器的训练完全独立于物体识别和分类而存在,可以并行。它的输入是目标检测训练数据集的图片在selective search之后的且与标注好的框的IOU大于0.6的proposal框,而它的label就是已经标注好的框。
Fast RCNN
论文见此
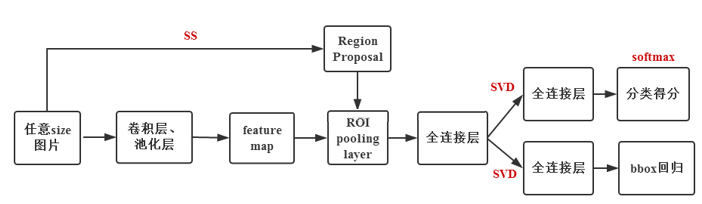
Fast RCNN的模型如下
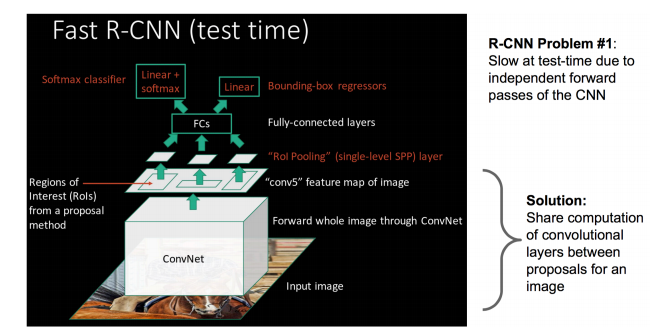
Fast RCNN对RCNN的改进
Fast RCNN是为了改进RCNN的缺陷而诞生的。RCNN的缺陷主要是:
1)Selective Search产生的每一个proposal框需要独自经过CNN来获得特征,计算量巨大
2)框物体识别和位置调整是分离的两个模型
基于上面两个缺点,Fast RCNN做了如下改进
1)先对图片整体经过CNN获得整体特征,再从中抠出proposal框,得到每一个框的特征。实现了卷积共享
2)使用multi-task的CNN网络,同时训练两种输出:物体识别和框位置调整
ROI Pooling Layer
Fast RCNN对RCNN的第一个改进是卷积共享。卷积共享之后,是如何再提取proposal框的图像特征呢?
假设原始图片的shape是1000*1000,某个proposal框的对角顶点坐标在(300,400)和(600,500)。图片在进行卷积之后的到的数据为100*100,那么上述的proposal框的对角顶点在当前数据上的映射为(30,40),(60,50),如此我们便拿到了卷积共享之后的proposal框特征。
不同shape的proposal框映射出了不同shape的特征。如果要将这些特征输入到后续的全连接层的话,那么全连接层的参数个数是未知的,是无法提前定义的。所以为了保证正常的网络构建,需要把特征们统一化一个shape上去。于是ROI Pooling层被引入了。
ROI Pooling实现的是一种特殊的max pooling,它能够将任何shape的矩阵进行分割,最大池化到目标shape的矩阵:
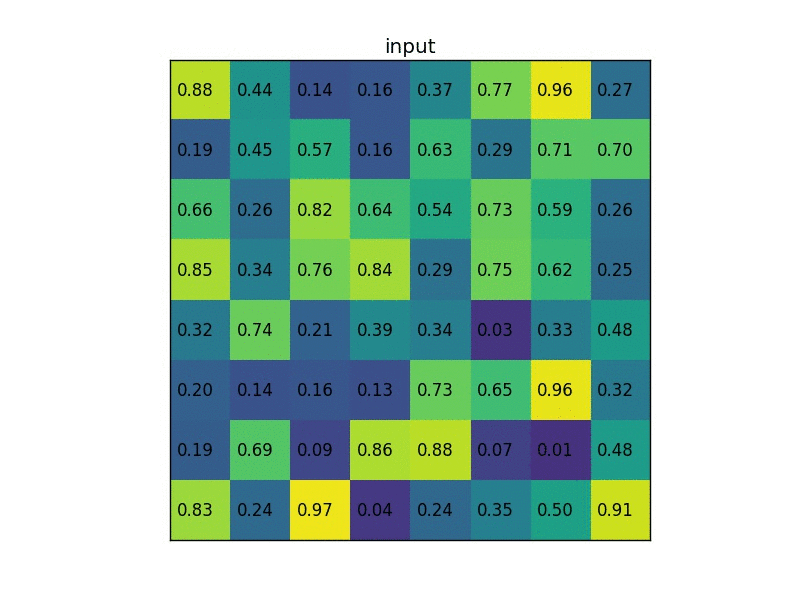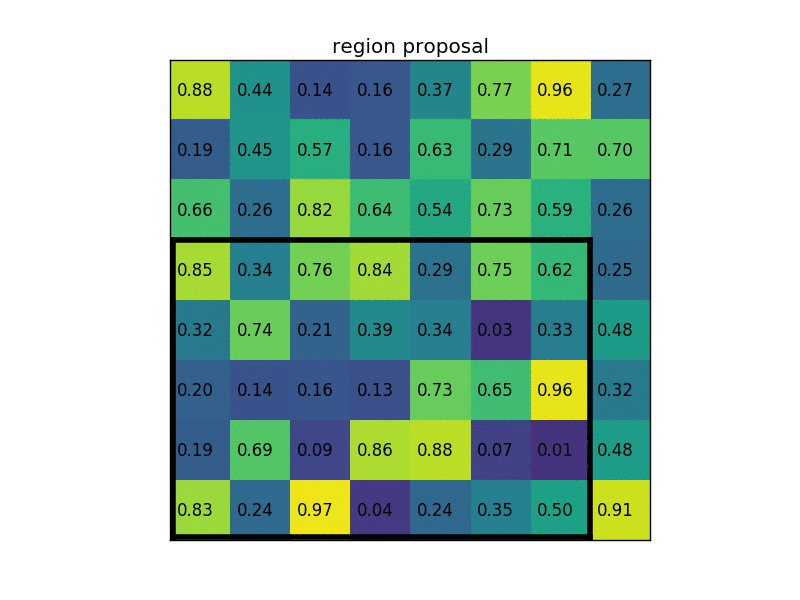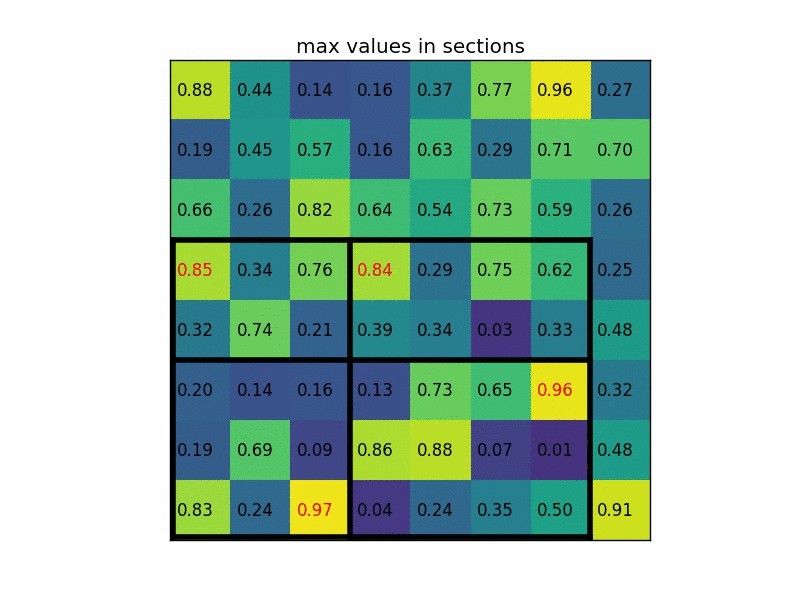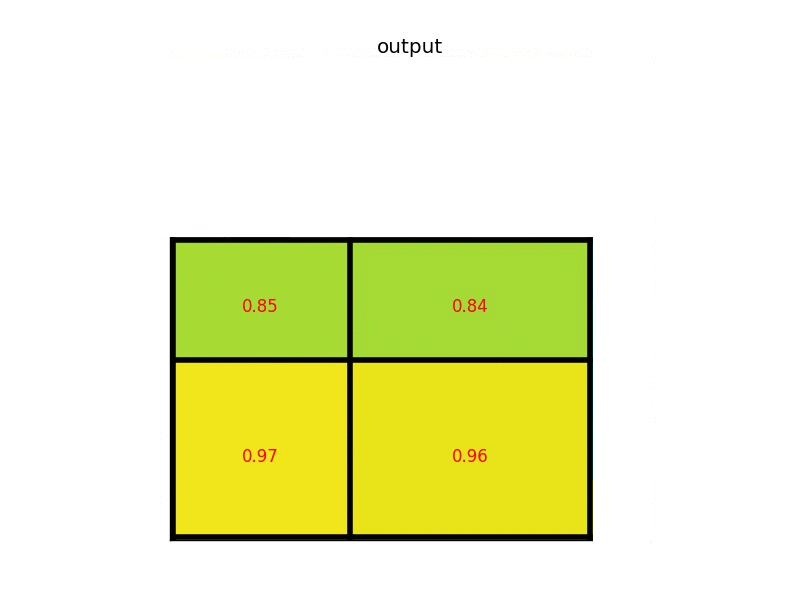
Multi-task
在Fast RCNN中,不在需要把proposal的位置输入到SVM来进行位置回归,它和proposal的图像特征一起通过CNN网络(不同的参数)并最后通过softmax输出。这种方式称作Multi-task
这里的多任务是从全连接层开始的。因为proposal框是非常多的,可以预见全连接层的参数非常多,所以整个网络的训练和预测在全连接环节的计算量非常大。这里Fast RCNN的作者很聪明地想到了用SVD进行降维。在之前的文章中我们讲过,SVD可以将矩阵进行奇异值分解,并通过取部分奇异值及其对应维度的方式,在可以承受的信息损失下进行矩阵的降维:
Faster RCNN
论文见此
Faster RCNN的流程图如下:
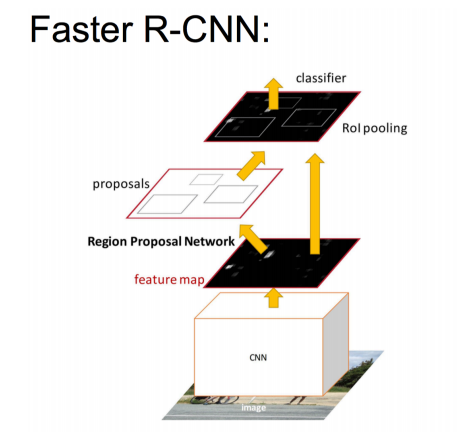
网络细节如下:
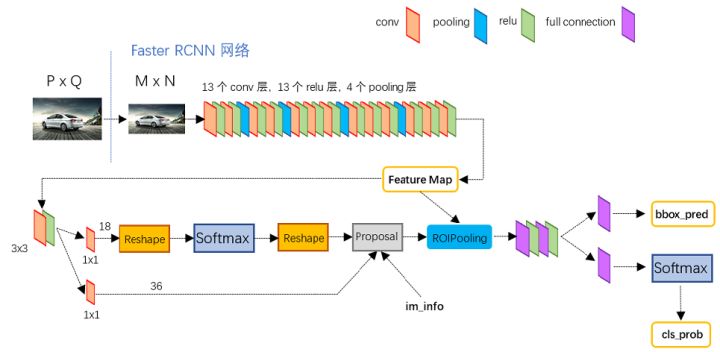
Faster RCNN是Fast RCNN的改进版。改进了什么呢?
Fast RCNN以及RCNN都使用了Selective Search进行proposal框图的选择,而在选择出来的框图被投入到后续的CNN模型中进行特征提取。利用成熟的Selective Search方法,省去了很多细节的工作,但是却带来了更多的计算量:因为Selective Search本身就进行了图像的特征分析和提取,这与后面使用CNN进行特征提取是有重复工作的。为了减少这个重复的工作,Faster RCNN直接弃用Selective Search,转而创造了Region Proposal Network(RPN)方法。
RPN
RPN是一种全卷积网络FCN, 它的流程图如下:
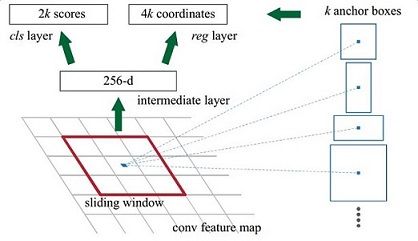
假设原图的shape为(N,M),在经过CNN的最后一个卷积之后得到feature map,shape是(N/16, M/16, 256),这里的256是它的通道数。
得到了feature map,开始进行RPN操作。
1)使用一个3*3的卷积核,对feature map进行卷积,得到的结果shape仍然是(N/16, M/16, 256)。另一种表述是:使用一个3*3的滑动窗口,对feature map进行扫描,每一次停留,对窗口内的图像进行一次全连接,这种表述是为了把焦点聚集在这个窗口的内容,而非整个feature map被卷积后的结果。
2)聚焦到每一个3*3的窗口上来。它进行全连接之后把3*3的矩阵转换成了一个数值,算上通道数,就是256个数值。这256个数值构成一个256维的特征向量。这个特征向量反映出feature map中3*3窗口里的图像信息,再进一步往回推,它反映了原图中48*48窗口里的图像信息。
3)以窗口的中心点为中心,在对应的原图上框出多个(比如9个)不同比例(1:1,2:1等等)和大小的候选框(称之为Anchor)。注意,候选框是对于整个原图而言的,可以大到覆盖整个原图,而不必限制在对应的滑动窗口中(即原图的48*48窗口):
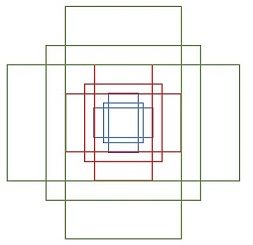
这样,整个原图会被画出N/16*M/16*9个Anchors
4)至此,对每个小窗口获取了两部分数据:1个特征向量,9个Anchor位置。对该特征向量分别进行两次全连接:全连接cls layer输出18个分数;全连接reg layer加上9个Anchor的位置信息,输出36个(x, y, w, h)这样的偏移量。
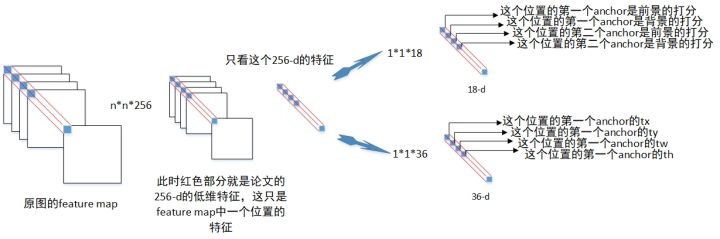
为什么一个256维的特征向量就能获得9个Anchor的信息呢?因为这个特征向量倒推回去到原图,其实包含了很大范围的图像,它即使没有覆盖每一个Anchor的面积,但至少包含了Anchor的很多部分,其次它定义了9个Anchor的中心。
RPN的训练
对于“是否为物体”识别器来说,训练数据是原始图片上被划分出来的Anchor,而label根据Anchor和原始图片上已经标注好的框的IOU而定,超过0.7为正,低于0.3为负,在这之间则该Anchor被丢弃。
对于位置回归器来说,训练数据是原始图片上被划分出来的Anchor,label是图片上已经标注好的框中与Anchor的IOU超过0.7的框的位置信息。
Faster RCNN的训练
Faster RCNN相当于RPN和Fast RCNN的融合,他们共享了前部分的CNN网络。那么要怎么训练这么一个融合模型呢?
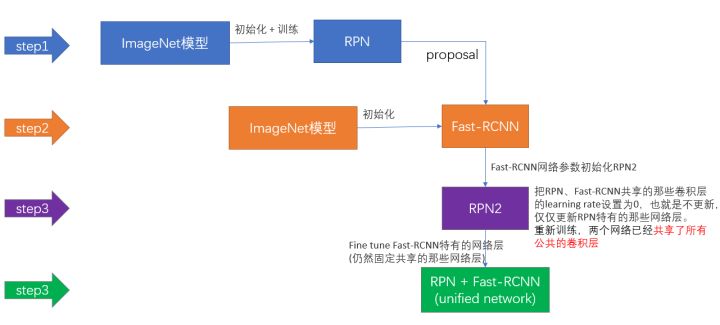
1)在已经被ImageNet数据集上预训练过(获取判断是否是背景的能力)的模型上,训练RPN网络,获得proposal预测能力
2)获取proposal,然后第一次训练Fast RCNN网络,更新共享CNN参数
3)使用更新了的共享CNN参数,第二次训练RPN网络,这次训练不再更新共享CNN参数,只更新RPN独有的部分
4)再次训练RPN网络,收集proposals
5)利用收取的proposals,第二次训练Fast RCNN网络
以上。
参考
https://www.cnblogs.com/skyfsm/p/6806246.html
https://zhuanlan.zhihu.com/p/43619815
https://blog.csdn.net/lanran2/article/details/54376126
https://zhuanlan.zhihu.com/p/30720870