问题的提出
问题来自于Kaggle的一个Titanic的竞赛项目:
给出泰坦尼克号上的乘客的特征(舱位,年龄,性别等),预测Ta是否被选中上援救船
模型训练和预测代码在此(不包含本文中的分析绘图部分代码)
数据集的获取
数据集在这里可以下载
我们来看看训练数据(测试数据只是少了label所在的列)
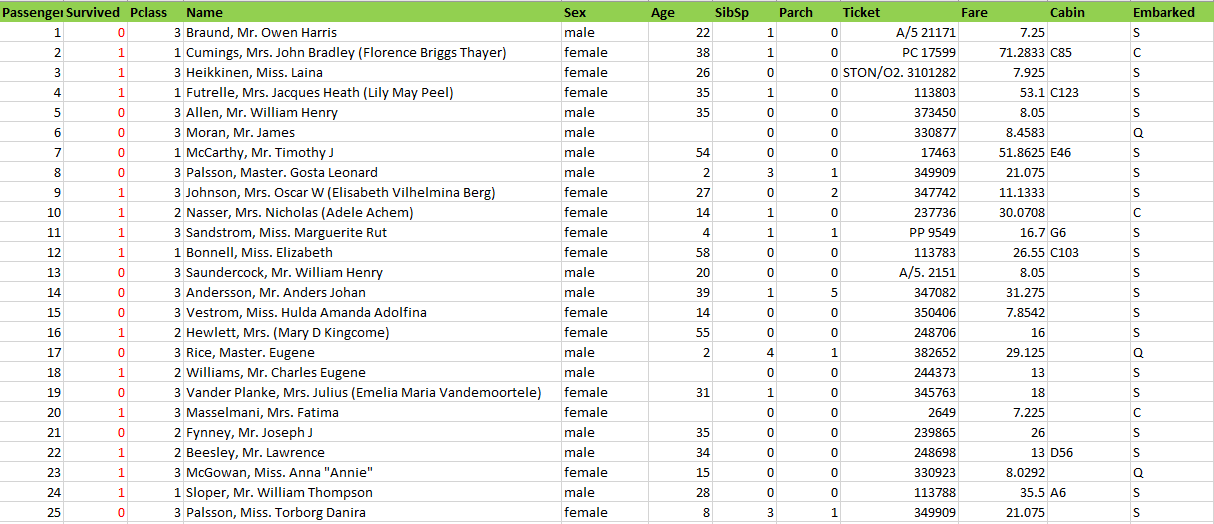
需要解释的列:
- Survived 列为是否被解救的label
- pclass 舱位等级
- SibSp 同船配偶以及兄弟姐妹的人数
- Parch 同船父母或者子女的人数
- Fare 船票价格
- Cabin 舱位
- Embarked 登船港口
代码
1 | import pandas as pd |
特征工程
为什么要进行特征工程? 因为特征众多,干扰也多,并不是所有特征都是需要保留的;需要保留的特征也并非直接可用的(比如需要进行数值转换,需要字符串截取);并不是所有特征都是有数据的(需要进行数据补全,或者直接舍弃该特征)
首先对训练数据有个大致的轮廓:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21train_test_df.info()
############################输出如下#################################
from numpy.core.umath_tests import inner1d
<class 'pandas.core.frame.DataFrame'>
Int64Index: 1309 entries, 0 to 417
Data columns (total 11 columns):
PassengerId 1309 non-null int64
Pclass 1309 non-null int64
Name 1309 non-null object
Sex 1309 non-null object
Age 1046 non-null float64
SibSp 1309 non-null int64
Parch 1309 non-null int64
Ticket 1309 non-null object
Fare 1308 non-null float64
Cabin 295 non-null object
Embarked 1307 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 122.7+ KB
None
可以看到Age,Fare,Cabin,Embarked是有缺失值的
Pclass
Pclass在数据集里面只有1,2,3三个值,且没有缺失值,可以直接用来训练。查看它对生还率的影响1
2
3
4
5
6
7import pandas as pd
from matplotlib import pyplot as plt
import numpy as np
# 查看对生还率的影响,只能通过训练数据,因为测试数据没有label
pd.crosstab(train_df['Pclass'],train_df['Survived']).plot(kind='bar')
plt.show()
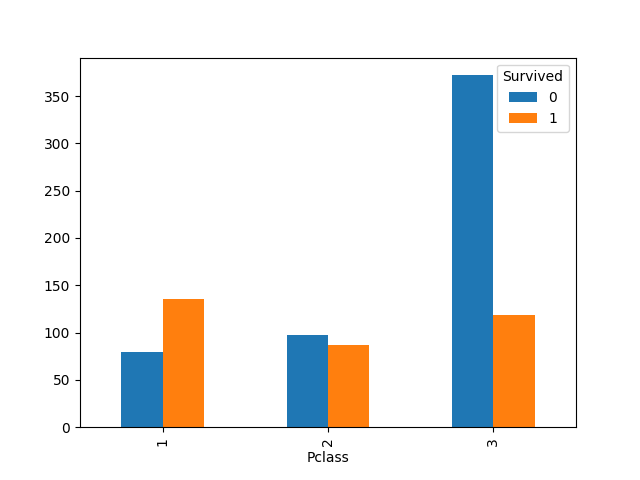
可见,等级越低,生还率越低。
为了理解pd.crosstab做了什么,查看一下它的返回数据:
1 | print pd.crosstab(train_df['Pclass'],train_df['Survived']) |
Name
名字中的Mr. Mrs. Miss Rev. Dr.可能是身份的象征,它影响是否被解救的结果吗?我们可以通过数据可视化来观察:
1 | def findTittle(name): |
输出如下:
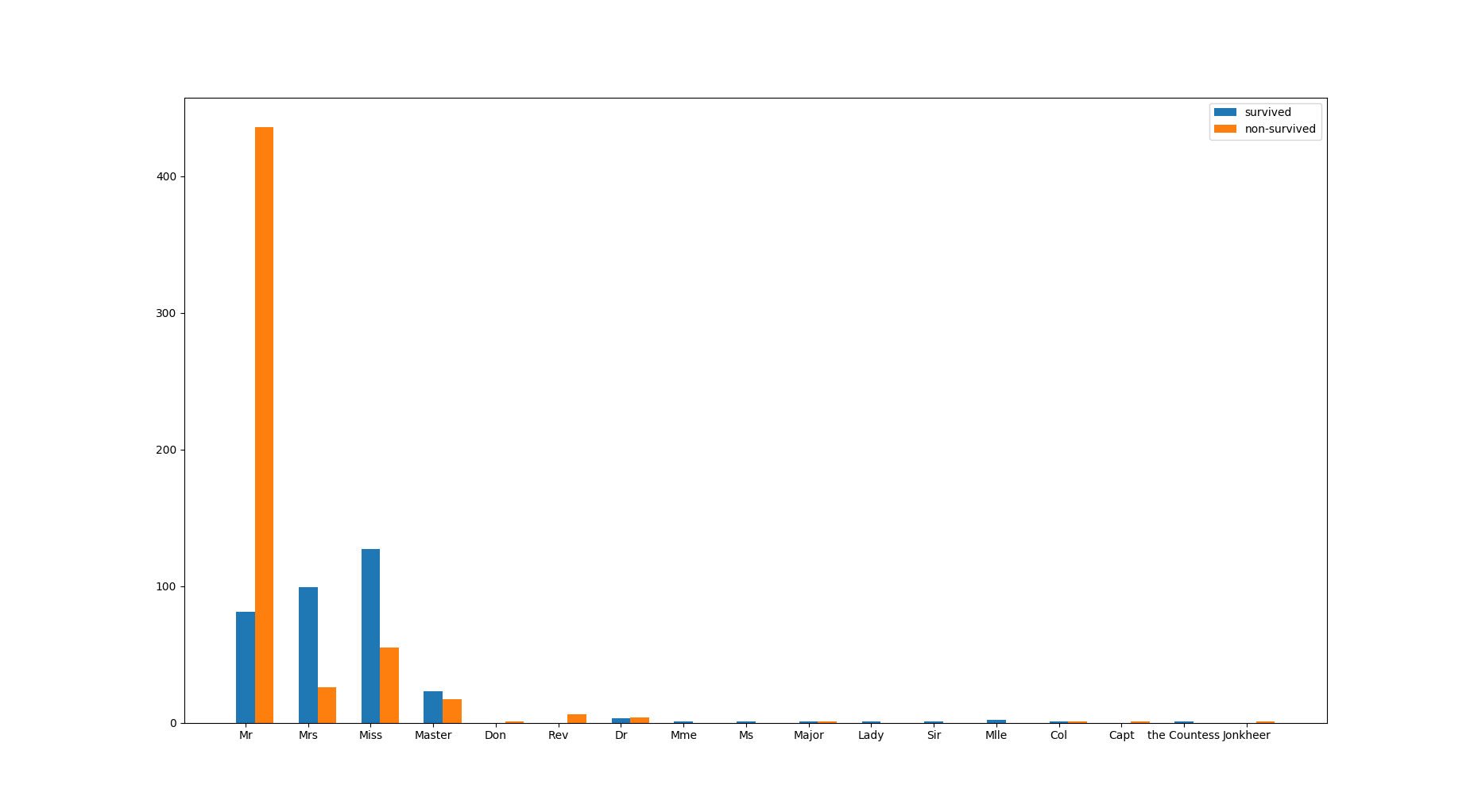
从图上看Mr生还率最低,而Mrs和Miss的生还率更高。所以title这个特征是可以影响到结果的。
Sex
第一反应会好奇是否女性会生还率更高?我们还是通过数据来观察:
1 | pd.crosstab(train_df['Sex'],train_df['Survived']).plot(kind='bar') |
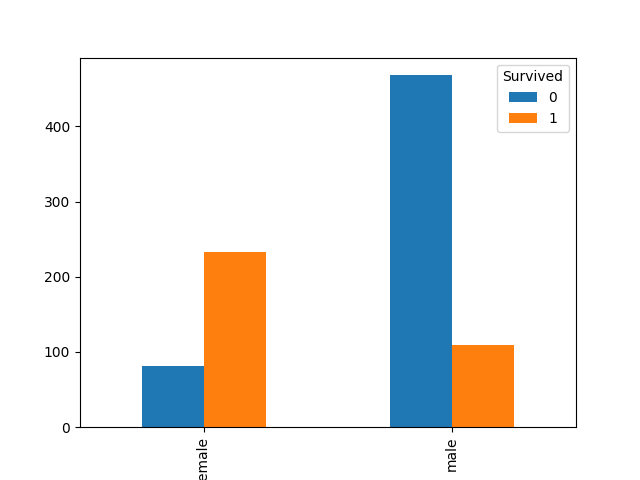
的确女性生还率更高,所以性别对结果有影响。
Age
首先年龄有缺失值,需要进行缺失值处理;其次年龄跨度很大,数值众多,为了简化计算同时减少过拟合,需要对年龄进行分段。
首先看缺失值补全。
缺失值怎么补全?根据实际需要可以补零,显然这里不适用;可以补充平均值,作为年龄的话也不是很合理;可以联合其他跟年龄有关的特征,比如上面讲的title来分别对不同的title求平均,这里我们选用这个方法。
1 | # 根据Name来分类,返回DataFrameGroupBy格式数据,是一种中间格式,不能打印 |
groupBy数据 在进行任何操作比如mean()之前只能是中间数据。
groupby的操作图如下:
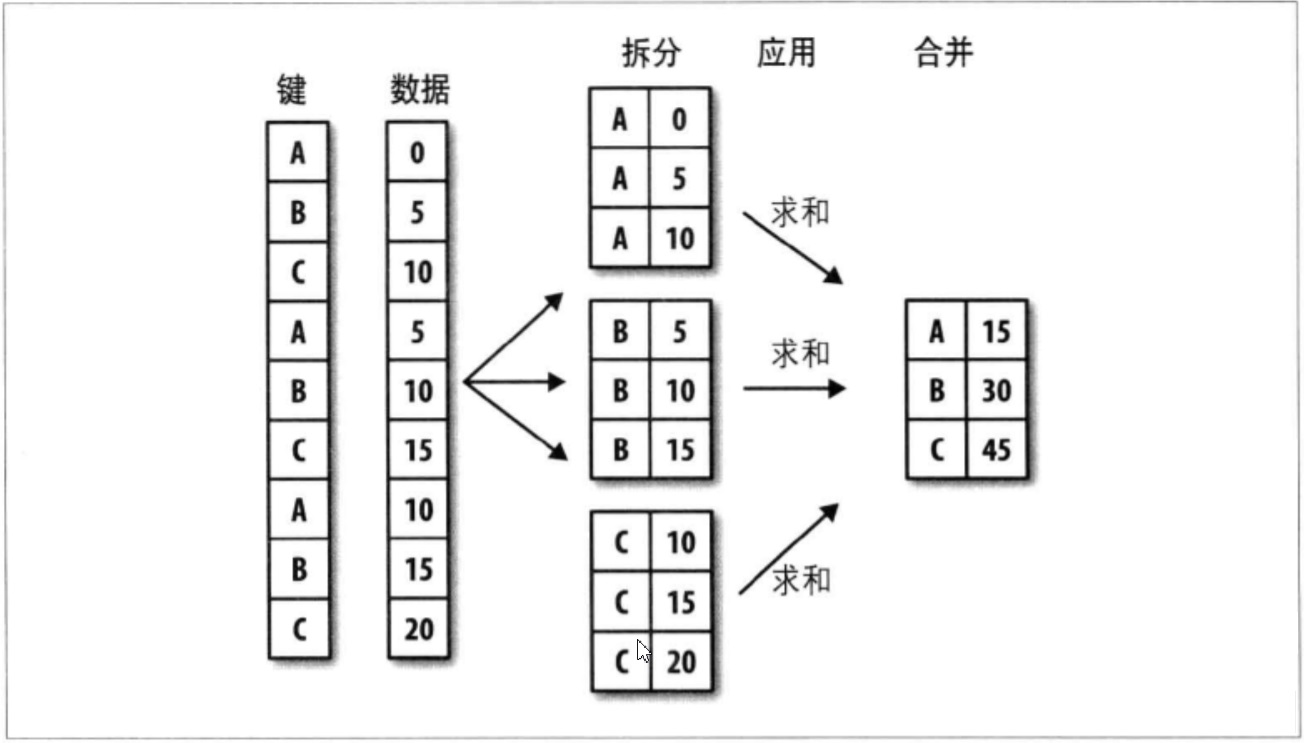
接下来进行年龄分段
1 | # 查看最大最小年龄,以确定分段的首尾 |
绘制图如下:
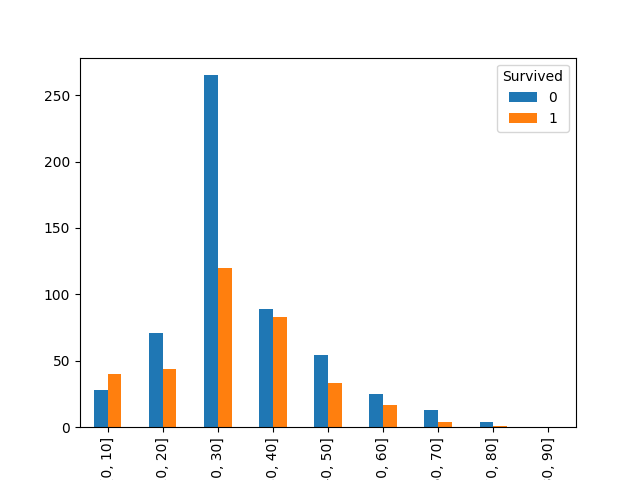
可见儿童的生还率更高。
SibSp
SibSp 没有缺失值,且已经是可使用的特征编码,来看看它对结果的影响
1 | sibSp_Survived = pd.crosstab(train_df['SibSp'], train_df['Survived']) |
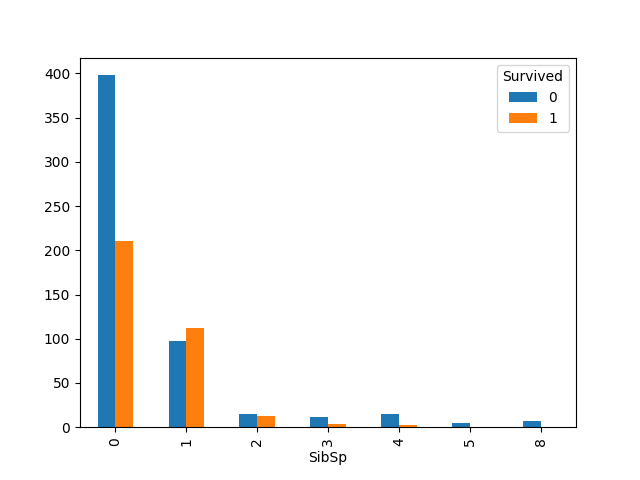
可见当SibSp为1,2时,生还率比较高。
Parch
Parch 没有缺失值,且已经是可使用的特征编码
1 | sibSp_Survived = pd.crosstab(train_df['Parch'], train_df['Survived']) |
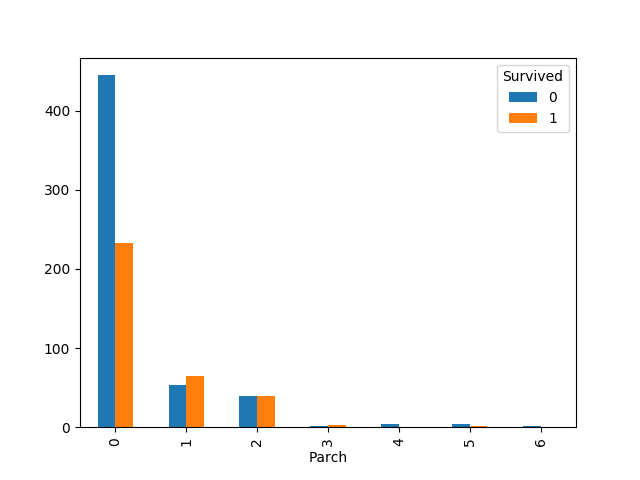
Ticket
1 | print train_test_df["Ticket"].describe() |
因为只有929张票号,意味着有人共用船票。共用船票可能是一个影响结果的新的特征,我们区分来看看:
1 | # 按照船票分组,as_index = Fals意味着船票也将作为一列,所以返回DataFrame而非Series |
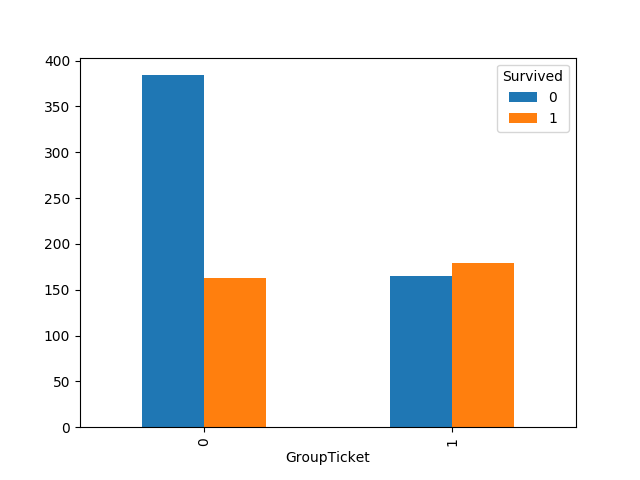
可以发现,共享票(有同伴)的生存率更高。
Fare
Fare是连续数值,有一个缺失值,需要补零之后(补零是因为空缺的Fare认为是无票或0价格票,再说空缺值只有1个),进行分段
1 | # 空缺值填补为0 |
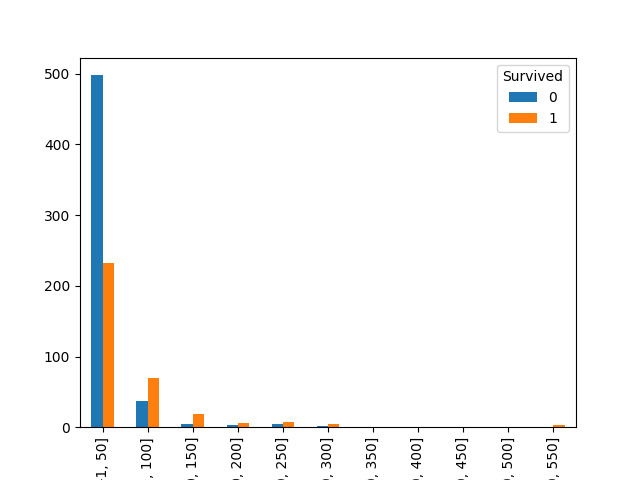
可见票价贵的,生还率相对更高
Cabin
Cabin含有大量的缺失值。我们是否要删掉这个特征呢?其实可以保留,因为确实的值是有信息的:可能他们属于没有舱位的散座乘客。那么我们可以把散座设置为“No”。同时我们猜想有舱位和无舱位应该是会有显著的差别的,所以我们可以确定区别之后,将特征简化为有无舱位两种值
1 | train_test_df['Cabin'] = train_test_df['Cabin'].fillna("No") |
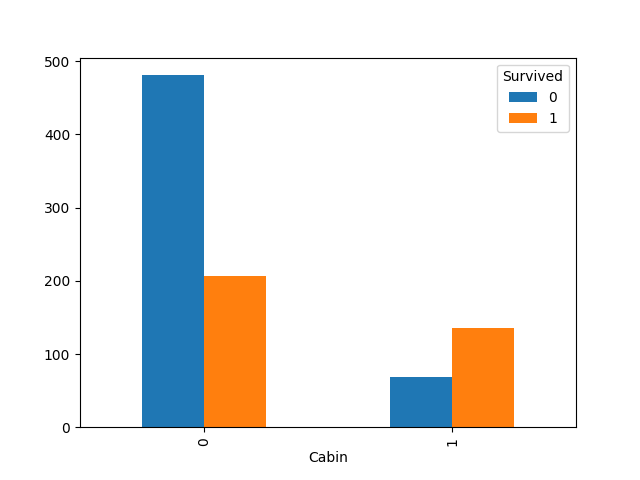
可见的确无舱位的生还率大大低于有舱位的。我们接受这次特征转换
Embarked
含有两个缺失值,可以通过众数来填补
1 | # Series调用mode函数,会返回Series格式的众数表格,而DataFrame会返回DataFrame |
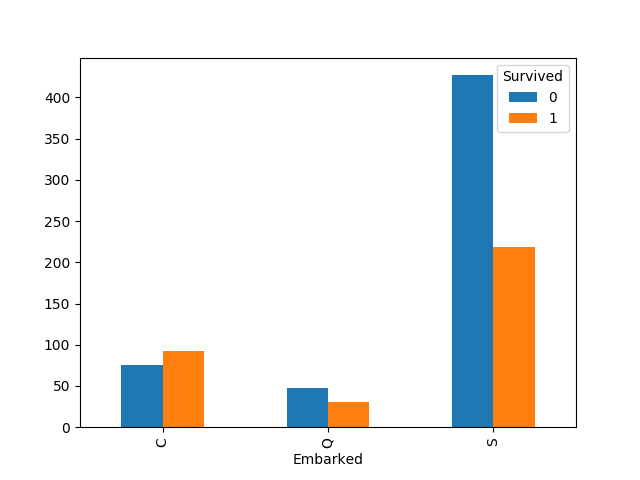
C港登船的生存率明显更大
创造新特征Family
我们发现SibSp和Parch两个意义一致,都是表示家庭成员,他们的图像也很相近。这个两个特征相关性非常高的,可以把它们合并为一个特征Family,用来表示家庭成员的个数
Family = SibSp + Parch + 1
1 | #创造新的特征 |
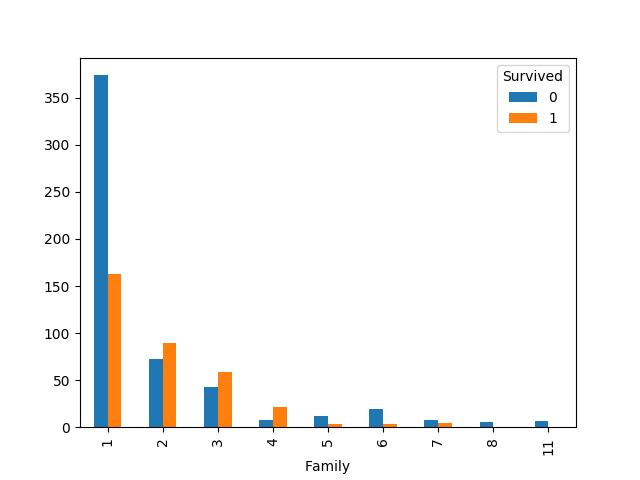
可见Family跟SibSp,Parch的图像相似,当独身一人时生还率比较低,当有一两个兄弟或父母在船上时,生还率比较高。
特征删除
到目前为止我们有下面的特征,且根据对结果是否有影响以及特征的合并,我们考虑是否删除该特征:
PassengerId 删除
Pclass 保留
Name 提取身份,保留
Sex 保留
Age 分段,保留
SibSp 删除
Parch 删除
Family 新建,保留
Ticket 转换为是否共享票,保留
Fare 分段,保留
Cabin 转换为是否有舱位,保留
Embarked 保留
1 | train_test_df = train_test_df.drop(["PassengerId","SibSp","Parch"],axis=1) |
特征量化
定性的特征需要转换为数值特征,以便进行特征分裂
1 | # 先获得类似{"Mr":0,"Miss":1}的字典,然后通过map来转换 |
训练和预测
特征工程完毕之后,再次把训练和测试数据分离1
2train_data_df = train_test_df[:len(train_data_df)]
test_df = train_test_df[len(train_data_df):]
进行训练和预测1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
# 从训练集里切割0.2为验证集,剩下0.8为训练集
X_train, X_test, Y_train, Y_test = train_test_split(train_data_df.values, train_label_data, test_size=0.2)
# 使用随机森林
rft = RandomForestClassifier(random_state=30)
rft.fit(X_train,Y_train)
# 用验证集进行评分
print rft.score(X_test,Y_test)
# 评分结果不固定,因为每次执行训练得到的模型不固定
###打印如下####
# 0.8324022346368715
# 预测
predict = rft.predict(test_df.values)
print predict
####打印如下####
# [0 0 0 0 0 0 1 0 1 0 0 1 1 0 1 1 0 0 0 1 0 1 1 0 1 0 1 0 0 0 0 0 1 1 1 0 0 0 0 1 0 1 0 1 1 0 0 0 1 1 0 0 1 1 0 0 0 0 0 1 0 0 0 1 1 1 1 0 1 1 1 0 0 1 1 0 0 1 0 1 1 0 1 0 0 0 1 0 1 1 0 0 1 0 0 0 1 0 0 0 1 0 0 0 1 0 0 0 0 1 0 1 1 1 1 0 0 1 0 1 1 0 1 0 0 0 0 1 0 0 0 1 0 0 0 0 0 0 0 0 0 1 0 0 1 0 0 0 1 0 1 0 0 1 0 0 1 0 0 0 1 1 1 0 0 0 0 0 1 0 0 0 0 0 0 1 1 1 1 1 0 1 1 0 1 0 1 0 0 0 0 1 1 0 1 0 1 0 0 0 1 1 1 1 0 0 0 0 1 0 0 0 0 1 1 0 1 0 1 0 1 0 1 0 1 1 0 1 0 0 0 1 0 0 1 0 0 0 1 1 1 1 0 0 1 0 1 0 1 1 1 0 0 0 0 0 0 0 1 0 0 0 1 1 0 0 1 0 0 0 0 0 1 1 0 1 0 0 0 0 0 1 1 1 1 0 0 0 0 0 1 1 0 1 0 0 1 0 1 0 0 0 0 0 1 1 1 1 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 1 1 0 1 0 0 0 1 1 0 1 0 1 0 0 0 1 0 0 0 1 1 0 0 1 0 1 1 0 0 0 1 0 1 0 0 0 0 1 1 0 1 0 0 1 1 0 0 1 0 0 1 1 0 0 1 0 0 0 1 1 0 1 0 0 0 0 0 1 1 0 0 1 0 1 0 0 1 0 1 0 0 0 0 0 1 1 1 1 0 0 1 0 0 1]
以上。