本文将用TensorFlow来实现CNN经典的入门项目:手写数字识别
数据集

手写数字的数据集来自著名的MNIST(美国国家标准与技术研究所),它包含了6万个训练样本和1万个测试样本,并且所有样本都已经标准化为28*28个像素,每个像素值在0~1之间。同时每张图片的储存方式已经扁平化为784(28*28)个元素的一维numpy序列。
网络结构
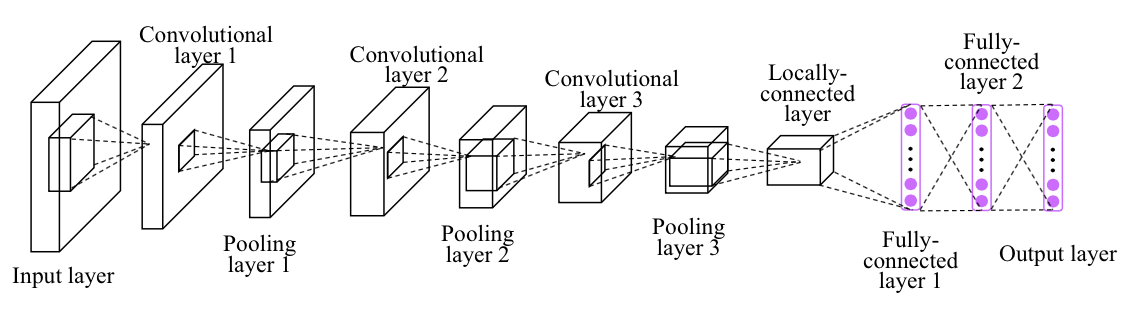
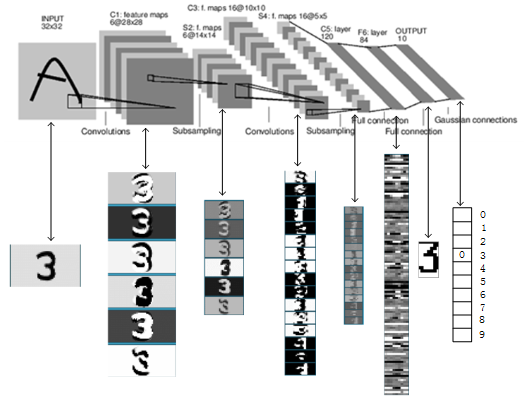
我们要构建的CNN网络大致如上,它实际上是使用了LeNet:
代码解析
完整代码见此
安装TensorFlow
1 | $ sudo pip install tensorflow |
获得数据集
开始我们的coding.
从TensorFlow获取
首先,获取数据集,可以通过tensorflow官方api直接拿到mnist数据集
1 | # 导入mnist数据集 |
从Kaggle比赛项目获取
本文中的完整代码是Kaggle比赛的项目,数据集在该比赛项目页面可以本地下载获得。下载得到的训练集为train.csv,测试集为test.csv
train.csv的格式如下,test.csv相比train.csv少了label列
1 | label pixel0 pixel1 pixel2 pixel3 ... pixel783 |
以上格式的csv可以通过pandas模块的read_csv读取:
1 | import pandas as pd |
代码解析
pandas中的数据结构
上面提到的DataFrame是pandas定义的一种格式,是一个类,这里csvDF是它的一个实例。在pandas常用的数据格式是三种:它自己的DataFrame,Series和numpy的ndarray。他们之间的关系可以描述如下:
DataFrame可以通过字典方式访问每一列,如csvDF[‘label’]或csvDF.label代表’label’所在的列,csvDF[‘label’]或csvDF.label就是Series格式的
对于DataFrame来说,直接取数值(即去掉表头): csvDF.values就得到了二维的numpy.ndarray格式数据;同理对于Series来说也可以去掉标注信息:csvDF[‘label’].values 获得一维度的numpy.ndarray格式数据。
多维数据在numpy.ndarray中的表示
numpy.ndarray中的多维数据是通过列表嵌套得到的。
表示一个shape为(9,)的数据:[1,2,3,4,5,6,7,8,9]
reshape为(3,3)的数据:[[1,2,3], [4,5,6], [7,8,9]]
reshape为(3,3,1)的数据:[[[1],[2],[3]], [[4],[5],[6]], [[7],[8],[9]]]
独热编码
(蓝色,红色,黄色)可以标签编码为(1,2,3),但是这样在计算上会造成 “(蓝色+黄色)/2=红色” 的不良后果。通过独热编码将它们映射到欧式空间可以解决这个问题:
蓝色=(1,0,0)
红色=(0,1,0)
黄色=(0,0,1)
在本文中,我们的label已经是0~9的数字,可以作为标签编码使用。但是考虑到神经网络最后有10个输出,为独热编码形式,所以这里我们使用独热编码来表示。
验证集分割
将训练集分割为实际训练集和验证集,为常用的训练前数据的准备方法。我们的训练过程通过考察该验证集的预测准确率来决定是否停止,而不是考察实际训练集的准确率。这样可以有效地减少过拟合可能。
1 | import numpy as np |
上面代码中np.delete接受的三个参数分别为:numpy.ndarray类型的待切割数据集,list类型的被删除的行(列)的列表,指定删除行(0)或列(1)
而上面使用的np.s_[0:1000]有特殊的功能,它是指取得指定范围的标号列表,也就是[0,1,2,3,…,999]
使用TensorFlow构建CNN网络
TensorFlow构建网络的方式大体上分两个步骤:1)先通过创建占位符号,构建图 2)然后在运行图的时候将数据喂进去,实现训练和预测。
构建图的过程是设计网络的过程,这中间用到的数据变量,都是“空壳”,它们占用了内存,但是里面并没有数据。运行的图的时候一定要喂数据,否则空图是不能运行处结果的。
1 | import tensorflow as tf |
代码讲解
tf.nn.conv2d函数
conv2函数里的参数strides表示卷积核的扫描步长,两边两个一般默认为1(因为不用对batch和channel方向做大于1的步长扫描),中间两个代表纵向和横向扫描的步长。如strides=[1,4,5,1]表示卷积核纵向一次移动4个元素,横向一次移动5个元素。
conv2函数里的参数padding=’SAME’代表通过补零方式,保证卷积输出的数据和原数据shape保持一致,否则padding=’VALID’表示不补零,数据输出将有shape损失。它的效果在之前的文章中有过介绍
当被卷积数据和卷积核的shape分别为(None,28,28,1),(5,5,1,32),它们是怎么被conv2d函数完成卷积的呢?
在conv2d函数看来,(None,28,28,1)中第一个维度None被认为是batch数,喂数据的时候喂入多行数据的时候就是多个卷积操作平行进行,互不干涉。第二、三个维度被认为是二维数据的高和宽,也就是数据为28*28形状。第四个维度被认为是数据的通道数,比如一张shape为(2,2,3)的彩色图片数据为[[[123,111,88], [123,234,87]], [[88,65,29], [76,20,246]]],它是2*2大小,而每个元素又分成三部分,每部分是RGB的一个值。
(5,5,1,32)前两个维度被认为是每个卷积核的形状,第三个维度的值1是输入通道数,对应的是被卷积数据的通道数,而第四个维度的值32是卷积后输出的通道数。
综合描述(None,28,28,1)和(5,5,1,32)的conv2d操作,就是对多行28*28的1通道的图片,使用1*32个5*5的卷积核进行卷积。
图解卷积发生的方式:
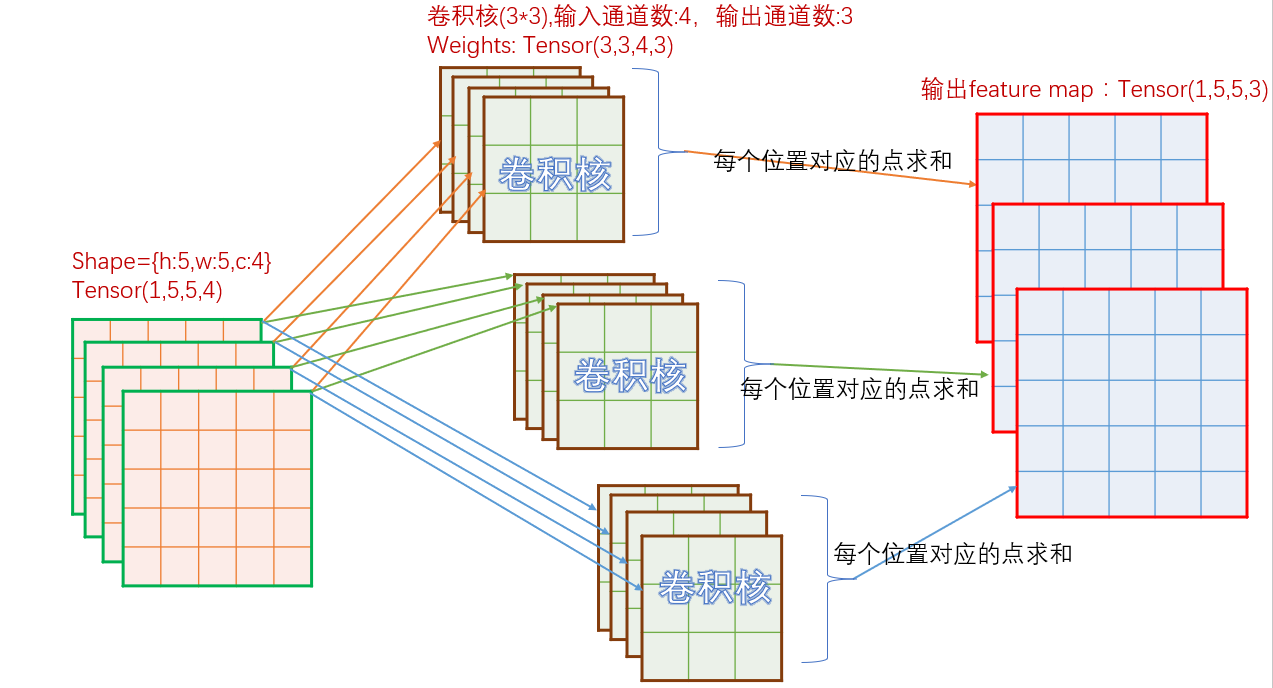
这里要着重理解一下卷积的分配方式和求和方式。思考一个问题:当我们把4个通道的图片进行conv2d操作之后变成了3个通道,这个过程中怎么对这4个通道都“公平”,并且求出来的3个通道也是公平的?
CNN的设计中实现了公平:对每个通道用不同的卷积核进行卷积,然后求和,这样形成一个新的通道。以上过程进行3次,得到3个通道。
之所以说对4个通道是公平的,是因为所有4个通道都被卷积,且没有一个通道被使用了特殊的卷积核,大家都是用随机的不同的卷积核,卷积完了进行求和,没有哪个的权重更大。
之所以说对生成的3个通道是公平的,是因为以上过程进行的3次重复,没有哪次的权重是更多的。
如果你能创造新的“公平”方式且能使得CNN的预测结果得到提升,那么恭喜你,你创造了一种CNN的改进算法。
tf.nn.bias_add函数
它是tf.nn.add的一种特例。tf.nn.add(x,y)的第二个参数y可以是单数值,这样话,该数值可以广播并相加到矩阵的任何一个元素上。
tf.nn.bias_add(x,y)的第二个参数y的维度必须跟x的最后一个维度是一致的
tf.nn.max_pool函数
进行最大池化的函数tf.nn.max_pool(value, ksize, strides, padding, name=None)
value为被池化对象;ksize=[1,height,width,1]表示池化窗口,因为不想在batch和channels上做池化,所以这两个维度设为了1;strides跟卷积一样,是每个维度上的步长;padding跟卷积一样,表示是否补零
比如shape为(1,4,4,2)的图片数据A,为: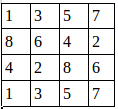
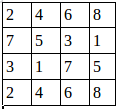
经过池化操作tf.nn.max_pool(A,[1,2,2,1],[1,1,1,1],padding=’VALID’)之后得到shape为(1,3,3,2)的图片数据: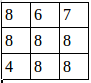
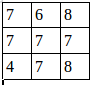
tf.nn.softmax函数
softmax对矩阵的每一行进行如下归一化操作,使得每一位都是相对于该行的概率(大小在0~1之间):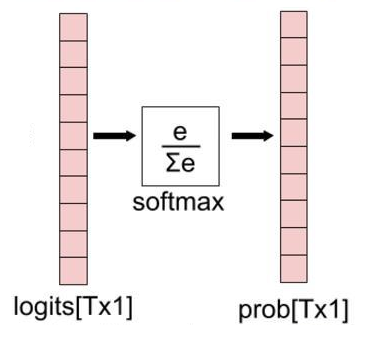
tf.nn.softmax_cross_entropy_with_logits_v2函数
tf.nn.softmax_cross_entropy_with_logits(logits, labels, name=None)用来计算交叉熵。
第一个参数logits是预测的分布,第二个参数label是真实的分布,他们的shape为(batchsize,num_classes),输出的shape为(batchsize,1)
交叉熵的公式是:
其中为真实的概率分布,
为预测的概率分布。
预测的概率分布越接近真实概率分布,则交叉熵越小。
训练和预测
1 | # 创建TensorFlow的会话,相当于初始化。 |
代码讲解
sess.run函数
sess.run(arg0, feed_dict=dict)第一个参数arg0为构建好的图或者多个图的列表,我们要run的就是这个arg0,run出结果之后函数返回也是这个arg0的计算值,feed_dict指定在运行过程喂数据的路径
tf.train.shuffle_batch函数
tf.train.shuffle_batch([train_data,train_labels],batch_size=1000, capacity=50000,min_after_dequeue=10000, enqueue_many=True) 工作方式为:
从420000条总数据里面,取出50000条数据组成一个小队列,并且打乱顺序,从队尾取出1000条数据,然后从总数据里面拿1000条过来补充到队头,再次打乱顺序,然后继续从队尾取出1000条,然后再打乱,再补充……当补充进来的数据超过了总数据,就再回到总数据的开始继续拿数据补充。
min_after_dequeue起的作用是要求capacity被取走batch_size的数据之后,队列里剩下的数据量要不小于min_after_dequeue
数据增强
在训练之前,我们可以通过Data augmentation获得更多的数据。数据更多当然就更有利于训练出精度更高,泛化能力更强的模型。
见代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46# 使用keras里的ImageDataGenerator函数进行图片增广
from keras.preprocessing.image import ImageDataGenerator
# 导入绘图工具
import matplotlib.pyplot as plt
import matplotlib.cm as cm
def augTrainData(train_data, aug_times=1):
print ("Before augmentaion: {0}, {1}".format(train_data.shape,train_labels.shape))
datagen = ImageDataGenerator(rotation_range=10, # 随机旋转10度
zoom_range = 0.1, # 随机缩放范围是±0.1
width_shift_range=0.1, # 随机水平移动范围是±0.1
height_shift_range=0.1) # 随机上下移动范围是±0.1
# 载入数据,生成迭代器,一次输出len(train_data)张图片,通过next()进行迭代
imgs_flow = datagen.flow(train_data.copy(), batch_size=len(train_data), shuffle = False)
# label直接复制,无需进行变换
labels_aug = train_labels.copy()
# 将数据扩展aug_times倍
for i in range(aug_times):
# 取出len(train_data)张图片
imgs_aug = imgs_flow.next()
# 增加行
train_data = np.append(train_data,imgs_aug,0)
train_labels = np.append(train_labels,labels_aug,0)
print ("After augmentaion: {0}, {1}".format(train_data.shape,train_labels.shape))
try:
print ("Trying to show augmentation effects")
# 用subplots绘制多个子图
# fig为整个图的对象,axs为多个(5*10)子图对象的二维列表,每个子图的高为15pixel,宽为9pixel
fig,axs = plt.subplots(5,10, figsize=(15,9))
# 对不同位置子图绘制图片
axs[0,1].imshow(train_data[len(train_data)//1000*1].reshape(28,28), cmap=cm.binary)
axs[0,2].imshow(train_data[len(train_data)//1000*500].reshape(28,28), cmap=cm.binary)
axs[0,3].imshow(train_data[len(train_data)//1000*999].reshape(28,28), cmap=cm.binary)
# 展示图片
plt.show()
except:
print ("No X server, skipping drawing")
train_data = augTrainData(train_data,1)
训练效果
1 | Before augmentaion: (32000, 28, 28, 1), (32000, 10) |
以上