聚类
K-means 是聚类算法。不同于分类,聚类是事先不知道有几类的情况下,将数据聚合成几个群体,相当于自己划出几个类出来,属于无监督学习。
K-means 算法流程
1)选质心:随机选取K个数据作为质心
2)聚集:对全局数据,计算质心之外的数据到K个质心的距离,到哪个质心距离最近就归到这个质心的团体中
3)选质心:得到了K个团体,对各个团体通过计算数据的平均值得到该团体新的质心(此时的质心很可能是虚拟点,即不存在原数据中)
4)重新聚集:对全局数据,计算质心之外的数据到K个质心的距离,到哪个质心距离最近就归到这个质心的团体中
5)验证:查看这次聚集的团体跟上次聚集的团体有没有变化。没有变化则结束,有变化则继续循环3)和 4)
通过图解就是:
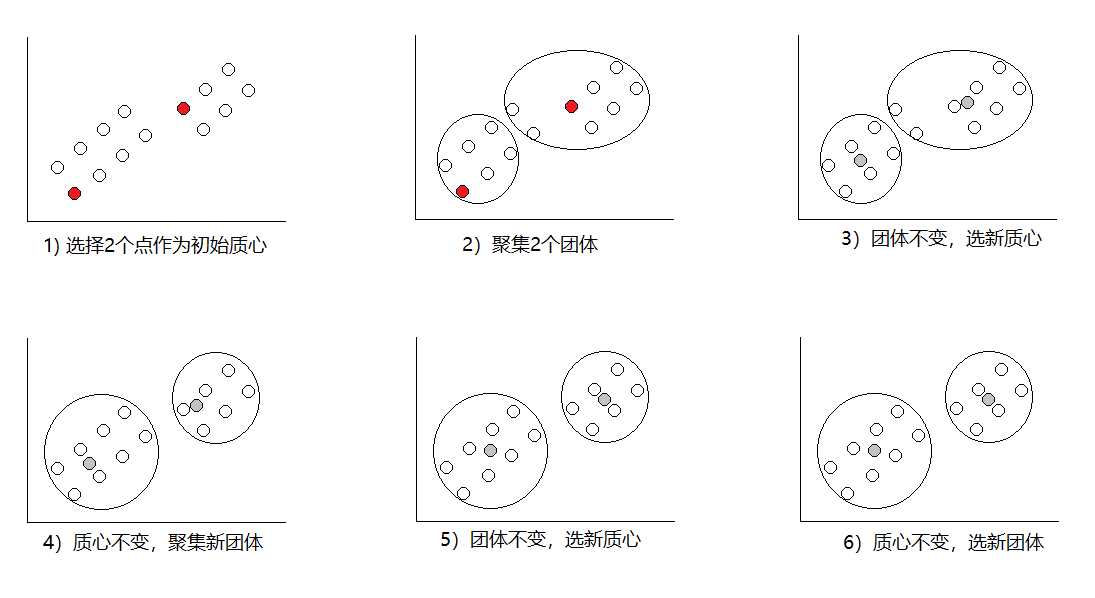
通过上图可以看到6)相对于5)的团体没有变化,所以已经收敛,聚类结束
实例
问题:将下面6个点聚类为2类
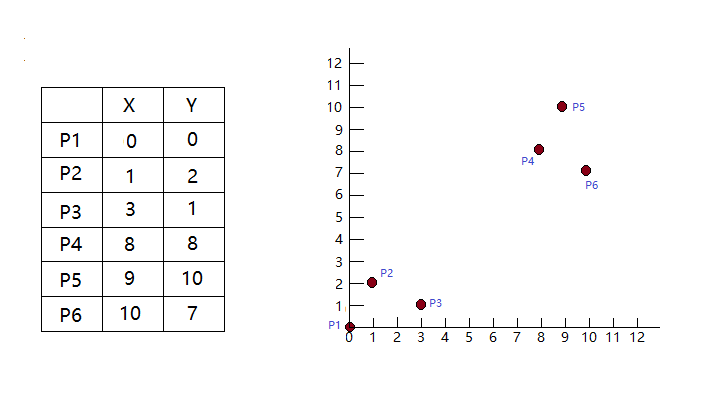
1)选择P1和P2为初始质心
2)通过计算其它点到质心P1, P2的距离来聚集团体:
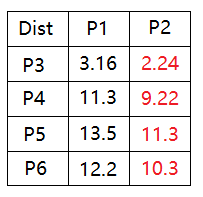
根据距离计算,得到两个团体:
A 团: P1
B 团: P2, P3, P4, P5, P6
3)对A, B团分别选新质心:
A团质心是P1自己,B团质心是PB=(6.2, 5.6)
4)围绕质心P1和PB,重新聚集团体:
首先距离计算为
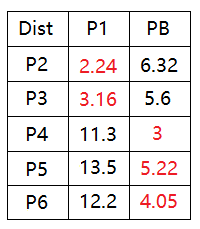
更新团体为:
C 团: P1, P2, P3
D 团: P4, P5, P6
团体相对A,B发生了改变,所以继续
5)对C, D团分别选新质心:
C团质心是PC=(1.33, 1), D团质心是PD=(9, 8.33)
6)围绕质心PC和PD,重新聚集团体:
首先距离计算为
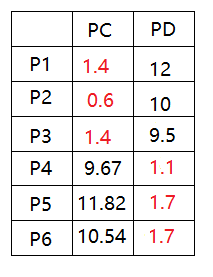
更新团体为:
E 团: P1, P2, P3
F 团: P4, P5, P6
团体相对C,D没有改变,所以已经收敛了。结束!
以上。