提升方法
对一个复杂任务来说,多个专家加权判断比一个专家单独判断效果要好,在机器学习中也一样。并且在机器学习中,训练一个高精度的模型比训练多个稍微粗糙的模型要困难得多,于是boosting(提升)方法被提出了。
提升方法在训练中主要需要解决两个问题:
1)数据的权重:基于什么原则向训练数据赋予权重;
2)分类器的权重:多个不同的弱分类器如何结合成为一个强分类器
AdaBoost很好地回答了上面两个问题。
AdaBoost提升方法
AdaBoost对上面两个问题的回答是:
1)数据的权重:在本轮训练中分类错误的数据被赋予更高的权重,以便在下一轮训练中被重点关照
2)分类器的权重:根据误差率赋予弱分类器权重,然后采用加权表决的方法获得强分类器
通过例子理解AdaBoost
有以下样本集,x为特征,y为分类值,共有-1,1两类,要求用AdaBoost训练一个强分类器

第1轮训练
1)初始化训练数据的权重:
其中
2)基于,计算特征x的哪个阈值使得分类误差最低。注意,一个阈值需要计算正向和反向两种情况:
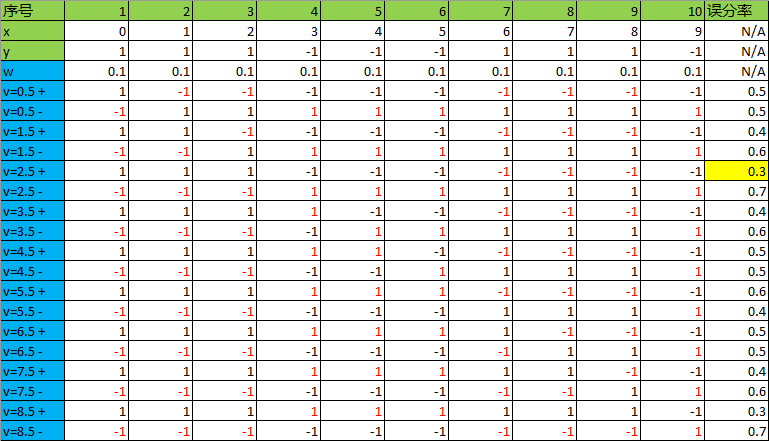
注意,计算时应乘以权重。
可见,当特征x的阈值为2.5或8.5时,误差率最低,为0.3,选择其中任何一个都可以,本轮选择v=2.5构建弱分类器:
3) 在训练数据集上的误差率为:
4)通过误差率计算弱分类器的权重系数:
5) 通过弱分类器加权获得强分类器:
加上信号函数才变成我们要的分类器决策函数:
6)测试一下强分类器对样本数据的分类能力:

有3个误分点,还需要继续boost
7)因为需要继续boost,根据本轮生成的弱分类器的错误率在强分类器里的权重,重新计算各数据的权重,供下轮训练使用:
更数据权重的公式为:
m表示下一轮是第m轮训练,i表示第i个数据。研究一下上面的公式,的正负代表该点(第i点)是否分类正确,所以它是用来当前点是被分对还是分错的,然后乘上本轮若分类器权重:
,就相当于在全局强分类器的角度看待当前点分类的对错。然后用自然对数底e作幂来获得当前数据权重更新的信息。至于为什么用自然对数,是基于数学家们的验证,这里不作证明。
据上公式,求第2轮的所有数据的权重:
第2轮训练
8)相当于回到2)开始循环,基于,计算特征x的哪个阈值使得分类误差最低:
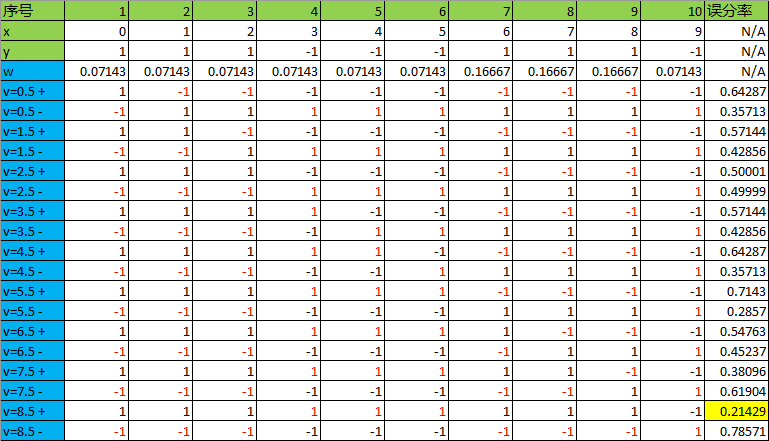
可见在8.5时候误分率最低,为0.21429,则本轮选择v=8.5构建弱分类器:
9) 在训练数据集上的误差率为:
10)通过误差率计算弱分类器的权重系数:
11) 通过弱分类器加权获得强分类器:
加上信号函数才变成我们要的分类器决策函数:
12)测试一下强分类器对样本数据的分类能力:

还有3个误分点,还需要继续boost
13)因为需要继续boost,根据本轮生成的弱分类器的错误率在强分类器里的权重,重新计算各数据的权重,供下轮训练使用:
根据,求第3轮的所有数据的权重:
第3轮训练
14)相当于再次回到2)开始循环,基于,计算特征x的哪个阈值使得分类误差最低:
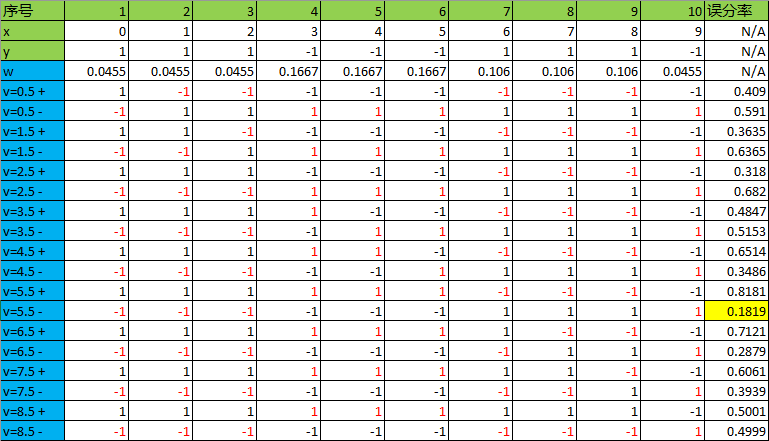
可见在5.5时候误分率最低,为0.1819,则本轮选择v=5.5构建弱分类器:
15) 在训练数据集上的误差率为:
16)通过误差率计算弱分类器的权重系数:
17) 通过弱分类器加权获得强分类器:
加上信号函数才变成我们要的分类器决策函数:
18)测试一下强分类器对样本数据的分类能力:

有0个误分点,boost结束!
以上。